-
티스토리 블로그 포스팅 글 목록 추출, 구글 애널리틱스 검색건수 찾기코딩 연습/코딩배우기 2021. 8. 5. 15:20반응형
[티스토리 블로그 포스팅 글 목록 추출, 구글 애널리틱스 검색건수 찾기]
티스토리 블로그에서 글들의 방문통계(일간, 주간, 월간)와 유입경로를 보다보면 아래와 같은 궁금증이 들 때가 많았다. 그래서 파이썬으로 블로그 포스팅 글 목록을 추출하고, 구글 애널리틱스의 페이지 뷰 데이터를 기준으로 인기 글 목록을 확인하는 작업을 해봤으며, 그 작업 내역을 포스팅 해보고자 한다.(티스토리 블로그는 "북 클럽" 스킨 기준)
- 지금까지 쓴 전체 글 목록을 한 번에 볼 수 있었으면... (어떤 글을 썼는지 전체 글 목록을 확인해 볼 수 있는 기능이 없다. 페이징은 되지만...)
- 방문통계나 페이지 검색 건수 등의 수치를 글 목록별로, 기간은 일/주/월을 넘어 원하는 만큼 설정해 볼 수 없나?
- 특히, 다른 사이트에 블로그를 개설할 때 내 블로그 포스팅 글 중 어떤 글이 인기가 있었는지 확인하고 싶은데... (티스토리 통계 메뉴에 일간/주간/월간 20건 현황은 보이지만...)
※ 여기서 블로그 포스팅 글 목록별 포스트 주소(URL)은 "숫자"인 경우임 (예로, https://everythings.tistory.com/123)
■ 티스토리 방문통계 (일간/주간/월간)

티스토리 방문통계 포털사이트 검색과 SNS별 방문통계가 집계되어 있고, 그 하위에 인기글 리스트 20건이 조회수와 함께 나온다.
포스팅 시작한지 1년이 되어가네~

■ 구글 애널리틱스(행동>사이트콘텐츠>모든 페이지)
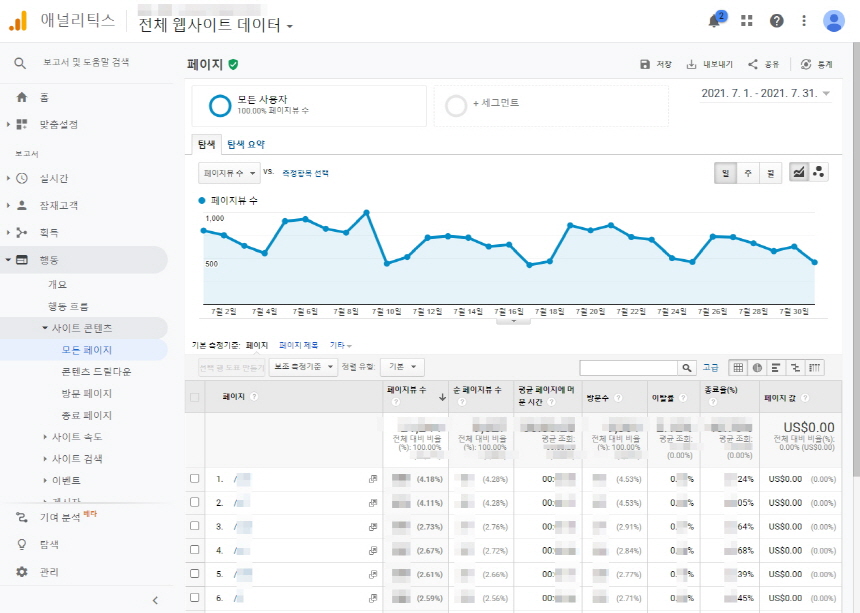
구글 애널리틱스(행동>사이트콘텐츠>모든 페이지) 티스토리 블로그 포스팅 글번호를 기준으로 데이터가 집계되고 있으며, 기간을 정하고 엑셀로 다운로드 할 수 있음.
(포스트 주소(URL)를 문자로 했을 경우, 어떻게 나오는지는 확인 못함)
■ 파이썬으로 티스토리 글 목록의 번호와 글 제목 가져와서 엑셀과 텍스트로 저장하기
from bs4 import BeautifulSoup import requests import openpyxl def tistoryTitle(post_num): ''' tistory 글 번호와 글 제목 가져와서 엑셀과 텍스트로 저장하기 ''' wb = openpyxl.Workbook() ws = wb.active # ws = wb['Sheet'] ws.cell(1, 1).value = '페이지 번호' ws.cell(1, 2).value = '글 제목' wb.save('tistory_title.xlsx') r = 2 # 엑셀 row 시작번호 for num in range(1, post_num + 1): url = 'https://everythings[본인의 티스토리명].tistory.com/' + str(num) response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') titles = soup.select('#content > div.inner > div.post-cover > div > h1') if not titles: # titles == [] 인 경우 continue tstory_title =titles[0].get_text() num_title = str(num) + '.' + tstory_title + '$' print(num_title) with open('tistory_title.txt', 'a', encoding='utf-8') as f: f.write(num_title) # 엑셀에 삽입 ws.cell(r, 1).value = num ws.cell(r, 2).value = tstory_title r += 1 wb.save('tistory_title.xlsx') wb.close() tistoryTitle(20) # 최근 글번호 입력 시 전체 내용 추출됨with open('tistory_title.txt', 'a', encoding='utf-8') as f: 에서
encoding='utf-8' 부분이 없을 경우 발생할 수 있는 오류
UnicodeEncodeError: 'cp949' codec can't encode character '\u2219' in position 7: illegal multibyte sequence저장된 엑셀 데이터와 구글 애널리틱스 자료(엑셀 다운로드)를 기준으로 인기있는 글을 확인할 수 있음(다만, 방문통계 중 구글 데이터만을 집계한 것이라는 점은 착안해야 함)
■ 응용 - 블로그 포스팅 카테고리별로 글 목록을 추출하기
from bs4 import BeautifulSoup import requests import openpyxl def tistoryCateTitle(): ''' tistory 카테고리별 글 번호와 글 제목을 가져와서 엑셀과 텍스트로 저장하기 ''' wb = openpyxl.Workbook() ws = wb.active # ws = wb['Sheet'] ws.cell(1, 1).value = '페이지번호&카테고리' ws.cell(1, 2).value = '글 제목' wb.save('tistory_category_title.xlsx') it_tip = 'https://[본인의 티스토리 카테고리 URL]' scrap = 'https://[본인의 티스토리 카테고리 URL]' coding = 'https://[본인의 티스토리 카테고리 URL]' life = 'https://[본인의 티스토리 카테고리 URL]' untact = 'https://[본인의 티스토리 카테고리 URL]' marketplace = '[본인의 티스토리 카테고리 URL]' category = [it_tip, scrap, coding, life, untact, marketplace] categ_titles = [] # 추출한 내용을 .txt 파일로 만들기 위한 리스트 for categ in category: for page in range(1, 50): # 페이지번호 1 ~ 최대값 입력 url = categ + '?page=' + str(page) response = requests.get(url) if response.status_code != 200: continue soup = BeautifulSoup(response.text, 'lxml') a_tags = soup.select('#content div.post-item > a') # print(len(a_tags)) if not a_tags: # titles == [] 인 경우 continue for tag in a_tags: ahref =tag['href'] title = tag.find('span', class_='title').text print(ahref) print(title) txt = ahref + '@' + title + '$' print(txt) categ_titles.append(txt) # 엑셀 작업 r = ws.max_row + 1 ws.cell(r, 1).value = ahref ws.cell(r, 2).value = title # break wb.save('tistory_category_title.xlsx') wb.close() for cateTitle in categ_titles: with open('tistory_category_title.txt', 'a', encoding='utf-8') as f: f.write(cateTitle) tistoryCateTitle()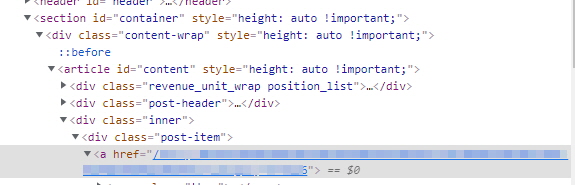
# 포스트 주소가 문자인 경우, 페이지 F12에서 추출할 a태그의 href 값이 문자(ASCII)로 되어있음
추출한 글 목록 전체를 가지고 티스토리 블로그 내에 '글목록 전체보기' 페이지를 만들수 있었음
반응형'코딩 연습 > 코딩배우기' 카테고리의 다른 글
파이썬으로 만든 이미지 다운로드 GUI (tkinter 모듈 사용) (0) 2021.08.22 네이버 블로그 글과 이미지 가져와서 백업하기(파이썬으로 작업) (2) 2021.08.18 파이썬 웹 호스팅(가비아) 운영 준비(소스파일 업로드), 서버 구동하기, 에러 메시지 조치... (0) 2021.08.02 NoReverseMatch ~ 파이썬 장고(django) 에러 (0) 2021.08.02 가비아 파이썬 웹 호스팅 사이트 운영을 위한 프로젝트 개발용 Anaconda 가상환경 생성과 PyCharm 설정 연습 (0) 2021.07.30