
goodthings4me.tistory.com
네이버 블로그 글과 이미지 가져와서 백업하기(파이썬으로 작업)
네이버는 블로그 글 저장 기능이 있다??
있다. pdf로...

그런데, 왜 이 짓을 했나...
원본 글과 이미지를 가지고 싶었고, 파이썬 코딩(스크래핑) 스터디 좀 하고 싶어서~

어떻게 했는지 살펴 보면...
네이버는 쉽게 스크래핑(크롤링) 하기 힘든 구조이다. 특히 초보자인 나로서는...
selenium으로 하면 어떨지...
그런데, selenium은 N이 싫어하고 잘 못 하면 막힌다는 얘기가 있었다.
그래서 난 일단 requests로 도전해보았다.
F12로 보이긴 했으나 페이지 소스보기에는 없는 구조! 헐~ 예상은 됐지만...
즉, 모두 js로 숨겨져 있는 듯.. 초보자인 나로서는 정말 쉽지 않았다.
그래도 포기란 없는 것....
blogId는 네이버 사용자의 id 인 듯,
logNo는 포스팅 페이지 번호 인 듯,
여러 번의 시행착오 끝에 간신히 페이지에 접근했다.
blogId는 페이지 URL에 그냥 나와있고,
logNo도 나와있지만, 스크래핑할 대상 페이지 번호이기 때문에 결과로 보는 단계가 아닌, get을 할 수 있는 URL을 만드는 것이 관건이었다.
먼저, 접근할 블로그 페이지는 카테고리와 페이지번호를 함께 볼 수 있는 URL을 찾아서
소스보기로 html 코드를 보면서 각 페이지의 logNo를 찾을 수 있는 태그를 잡아내야 했었다.
"https://blog.naver.com/PostList.naver?from=postList&blogId=블로그ID&categoryNo=카테고리번호¤tPage=페이지번호"
그 태그의 title 속성에서 logNo을 찾을 수 있었다.
https://blog.naver.com/블로그ID/페이지번호

글과 이미지를 추출할 수 있는 URL(title의 값(logNo= 포함))을 모두 가져온다.
<div class="blog2_post_function">
<a href="#" id="copyBtn_1121190014699" class="url pcol2 _setClipboard _returnFalse _se3copybtn _transPosition" title="https://blog.naver.com/블로그ID/1121190014699" style="cursor:pointer;">URL 복사</a>title 속성에서 페이지 URL 추출 시,
해당 블로그의 파라미터에서 categoryNo을 숫자 보다 좀 많게 잡아주고
페이지번호도 각 카테고리의 페이지 숫자 중 최대치를 잡아준 후
많아서 과하게 처리되는 부분은 제한을 걸어주어야 하고
페이지 내용이 없는 경우도 있으니 예외 처리가 필요하다.
가져온 각 포스팅 페이지 URL을 requests.get 처리로 전환한 후
페이지 소스보기를 통해 iframe에서 src를 찾고
<body>
<iframe id="mainFrame" name="mainFrame" allowfullscreen="true" src="/PostView.naver?blogId=블로그ID&logNo=1121190014699&redirect=Dlog&widgetTypeCall=true&directAccess=false"
scrolling="auto" onload="oFramesetTitleController.start(self.frames['mainFrame'], self, sTitle);oFramesetTitleController.onLoadFrame();oFramesetUrlController.start(self.frames['mainFrame']);oFramesetUrlController.onLoadFrame()" allowfullscreen></iframe>
</body>
다시 페이지 소스보기에서 이미지를 찾는다.
이미지는 <img src=""가 아닌 data-lazy-src="" 부분을 가져와야 큰 이미지임
<div class="se-module se-module-image" style="">
<a href="#" class="se-module-image-link __se_image_link __se_link"
<img src="https://postfiles.pstatic.net/MjAyMDEyMDVfMTYy/MDAxNjA3MTcyNDAwNzM3.1DNdDwh26ATRDxCoEm8e-bpHFmG3njqawGjqulOZsRAg.W2QhBUifWYhSYE36SHbKjZjxeYg.JPEG.ㅁㅁㅁㅁ/20201205%EF%BC%BF125.jpg?type=w80_blur" data-lazy-src="https://postfiles.pstatic.net/MjAyMDEyMDVfMTYy/MDAxNjA3MTcyNDAwNzM3.1DNdDwh26ATRDxCoEm8e-bpHFmG3njqawGjqulOZsRAg.WvlABUhW2QhBUifWYhSYE36SHbKjZjxeYg.JPEG.ㅁㅁㅁㅁ/20201205%EF%BC%BF125.jpg?type=w966" data-width="900" data-height="1200" alt="" class="se-image-resource" />
그리고, 글은 id가 아닌 class로 <div>태그에서 가져왔다.
<div class="se-component se-text se-l-default" id="SE-bab00-37-11eb-a35-8f7feb41c">
<div class="se-component-content">
<div class="se-section se-section-text se-l-default">
<div class="se-module se-module-text">
<!-- SE-TEXT { --><p class="se-text-paragraph se-text-paragraph-align-
<span style="" class="se-fs- se-ff- " id="SE-7e-367-11b-335-dd5d33bfc1">여름의.... </span></p>

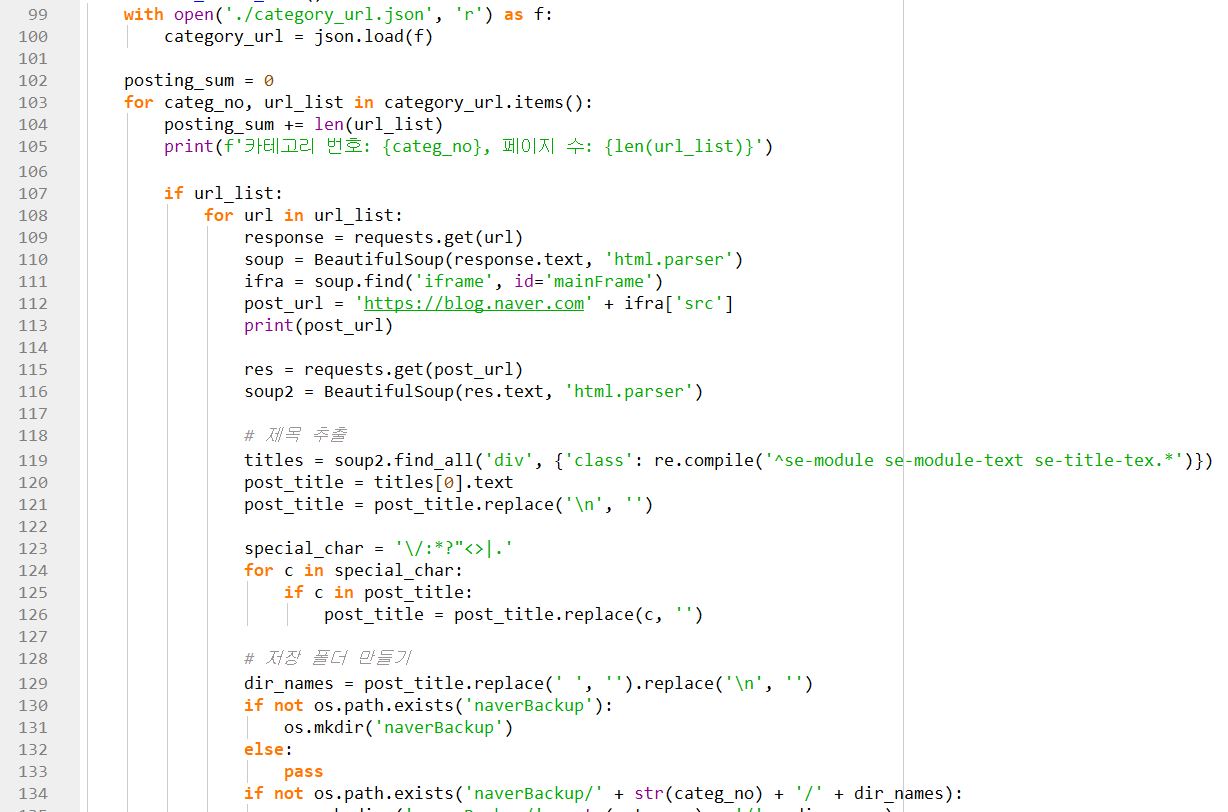
그래서, 일단은 성공했다.
네이버 페이지 소스(html)가 바뀌면 또 허당이지만.....
그리고, 위 내용과 유사하게 네이버 블로그 페이지 URL을 입력하면 블로그 내용과 이미지를 추출해주는 프로그램을 파이썬 Tkinter로 만들어 보았다.

※ 네이버 블로그 저장 프로그램 다운로드 : 여기(클릭)
네이버 블로그의 전체 페이지 저장하기(방법 설명)
하나의 네이버 아이디로 작성한 블로그 전체 페이지에 대해 콘텐츠를 저장하려면 글 전체보기의 목록에서 각 리스트의 블로그 주소(URL)를 추출하고, 해당 블로그 페이지를 순환
goodthings4me.tistory.com
'코딩 연습 > 코딩배우기' 카테고리의 다른 글
| API를 잘 모르면서 해본 '쿠팡 파트너스 API' 실습 (0) | 2021.08.23 |
|---|---|
| 파이썬으로 만든 이미지 다운로드 GUI (tkinter 모듈 사용) (0) | 2021.08.22 |
| 티스토리 블로그 포스팅 글 목록 추출, 구글 애널리틱스 검색건수 찾기 (0) | 2021.08.05 |
| 파이썬 웹 호스팅(가비아) 운영 준비(소스파일 업로드), 서버 구동하기, 에러 메시지 조치... (0) | 2021.08.02 |
| NoReverseMatch ~ 파이썬 장고(django) 에러 (0) | 2021.08.02 |




댓글