
goodthings4me.tistory.com
유튜버 '나도코딩'님의 파이썬 무료 강의 활용편 5번째인 "데이터 분석 및 시각화"에 대한 영상 자료를 연습한 내용을 정리함.
판다스(Pandas )로 데이터 분석해보기
▣ Pandas란?
- Pandas는 파이썬에서 사용하는 데이터 분석 라이브러리이다.
- 우리가 엑셀이나 RDBMS에서 사용하는 데이터는 보통 행과 열로 된 2차원 구조로 되어있는데 이런 데이터를 쉽고 간편하게 다룰수 있고, 특히 용량이 큰 데이터들도 안정적으로 처리할 수 있다.
- 파이썬에서 데이터 분석을 한다는 것은 판다스를 사용한다는 의미로 볼 수 있다.
- Pandas 설치 : pip install pandas
▣ Series
- 1차원 데이터(정수, 실수, 문자열 등)를 처리하는 판다스의 Series 클래스
- Series 객체 생성은 리스트를 인자로 하여 생성함
temp = pd.Series([-20, 10, 10, 20])
print(type(temp))
print(temp)
print(temp[1]) # index 1에 해당하는 데이터 출력
'''
<class 'pandas.core.series.Series'>
0 -20
1 10
2 10
3 20
dtype: int64
10
'''# 맨 앞에 디폴트 index가 붙는다
# index는 데이터에 접근할 수 있는 주소 값
# 리스트를 인자로 받은 객체에서 1번째 index 추출 시 temp[1] 사용
▷ Index를 다른 것으로 지정하여 Series 객체 생성
# index=[] 요소 추가해서 표현하기
temp = pd.Series([-20, 10, 10, 20], index=['Jan', 'Feb', 'Mar', 'Apr'])
print(temp)
print(temp['Apr']) # index Apr에 해당하는 데이터 출력
'''
Jan -20
Feb 10
Mar 10
Apr 20
dtype: int64
20
'''▣ DataFrame
- 2차원 데이터 처리하는 판다스의 클래스
- Series의 연속적인 모음이며 Series의 합이다.
- DataFrame에서 다루는 Data 준비 : 사전(dict) 자료구조를 통해 생성함
data = {
'이름' : ['채치수', '정대만', '송태섭', '서태웅', '강백호', '변덕규', '황태산', '윤대협'],
'학교' : ['북산고', '북산고', '북산고', '북산고', '북산고', '능남고', '능남고', '능남고'],
'키' : [197, 184, 168, 187, 188, 202, 188, 197],
'국어' : [90, 40, 80, 40, 15, 80, 55, 100],
'영어' : [85,35, 75, 60, 20, 100, 65, 85],
'수학' : [100, 50, 70, 70, 10, 95, 45, 90],
'과학' : [95, 55, 80, 75, 35, 85, 40, 95],
'사회' : [85, 25, 75, 80, 10, 80, 35, 95],
'SW특기' : ['Python', 'Java', 'Javascript', '', '', 'C', 'PYTHON', 'C#']
}
print(type(data)) # <class 'dict'>

▷ DataFrame 객체 생성
df = pd.DataFrame(data) # DataFrame 객체 생성 - 인자로 dict 전달
print(df)
'''
이름 학교 키 국어 ... 수학 과학 사회 SW특기
0 채치수 북산고 197 90 ... 100 95 85 Python
1 정대만 북산고 184 40 ... 50 55 25 Java
2 송태섭 북산고 168 80 ... 70 80 75 Javascript
3 서태웅 북산고 187 40 ... 70 75 80
4 강백호 북산고 188 15 ... 10 35 10
5 변덕규 능남고 202 80 ... 95 85 80 C
6 황태산 능남고 188 55 ... 45 40 35 PYTHON
7 윤대협 능남고 197 100 ... 90 95 95 C#
[8 rows x 9 columns]
'''# key:value 사전(dict) 타입을 DataFrame 객체로 생성하면 key는 column(열)이 되고 value는 값이 됨
▷ DataFrame 데이터 접근
print(df['이름'])
'''
0 채치수
1 정대만
2 송태섭
3 서태웅
4 강백호
5 변덕규
6 황태산
7 윤대협
Name: 이름, dtype: object
'''
print(df['SW특기'])
'''
Name: 이름, dtype: object
0 Python
1 Java
2 Javascript
3
4
5 C
6 PYTHON
7 C#
Name: SW특기, dtype: object
'''
print(df[['이름', '키']])
'''
이름 키
0 채치수 197
1 정대만 184
2 송태섭 168
3 서태웅 187
4 강백호 188
5 변덕규 202
6 황태산 188
7 윤대협 197
'''# 2개 이상의 컬럼을 가져올 때 컬럼들을 리스트로 감싼 값을 df의 키로 넘져준다(대괄호 2개 사용)
▷ DataFrame 객체 생성 시 임의의 index 지정해서 표현하기
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번', '7번', '8번'])
print(df)
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
1번 채치수 북산고 197 90 85 100 95 85 Python
2번 정대만 북산고 184 40 35 50 55 25 Java
3번 송태섭 북산고 168 80 75 70 80 75 Javascript
4번 서태웅 북산고 187 40 60 70 75 80
5번 강백호 북산고 188 15 20 10 35 10
6번 변덕규 능남고 202 80 100 95 85 80 C
7번 황태산 능남고 188 55 65 45 40 35 PYTHON
8번 윤대협 능남고 197 100 85 90 95 95 C#
'''# 데이터 개수(Row)만큼 index를 지정해야 함
▷ DataFrame 객체 생성 시 column을 몇개만 지정해서 추출하기 (순서도 변경 가능)
df = pd.DataFrame(data, columns=['이름', '학교', '키'], index=['1번', '2번', '3번', '4번', '5번', '6번', '7번', '8번'])
print(df)
'''
이름 학교 키
1번 채치수 북산고 197
2번 정대만 북산고 184
3번 송태섭 북산고 168
4번 서태웅 북산고 187
5번 강백호 북산고 188
6번 변덕규 능남고 202
7번 황태산 능남고 188
8번 윤대협 능남고 197
'''
▣ Index에 대해 알아보기
- 인덱스 내용 보기 : 객체.index (예시: df.index)
- 인덱스 이름 지정 : 객체.index.name = '이름'
- 인덱스 초기화 : 객체.reset_index() 새로운 index가 생김
- 사용하던 인덱스 삭제 : 객체.reset_index(drop=True)
print(df.index)
# Index(['1번', '2번', '3번', '4번', '5번', '6번', '7번', '8번'], dtype='object')
df.index.name = '번호'
print(df)
'''
이름 학교 키
번호
1번 채치수 북산고 197
2번 정대만 북산고 184
3번 송태섭 북산고 168
4번 서태웅 북산고 187
5번 강백호 북산고 188
6번 변덕규 능남고 202
7번 황태산 능남고 188
8번 윤대협 능남고 197
'''
df = df.reset_index()
print(df)
'''
번호 이름 학교 키
0 1번 채치수 북산고 197
1 2번 정대만 북산고 184
2 3번 송태섭 북산고 168
3 4번 서태웅 북산고 187
4 5번 강백호 북산고 188
5 6번 변덕규 능남고 202
6 7번 황태산 능남고 188
7 8번 윤대협 능남고 197
'''# reset_index() 사용 시 기존 index '번호'는 일반 컬럼으로 됨
df = pd.DataFrame(data, columns=['이름', '학교', '키'], index=['1001', '1002', '1003', '1004', '1005', '1006', '1007', '1008'])
df.index.name = '수험번호'
print(df)
'''
이름 학교 키
수험번호
1001 채치수 북산고 197
1002 정대만 북산고 184
1003 송태섭 북산고 168
1004 서태웅 북산고 187
1005 강백호 북산고 188
1006 변덕규 능남고 202
1007 황태산 능남고 188
1008 윤대협 능남고 197
'''
df.reset_index(drop=True, inplace=True) # 인덱스 '수험번호' 삭제, inflace= 는 실제 데이터 바로 반영
print(df)
'''
이름 학교 키
0 채치수 북산고 197
1 정대만 북산고 184
2 송태섭 북산고 168
3 서태웅 북산고 187
4 강백호 북산고 188
5 변덕규 능남고 202
6 황태산 능남고 188
7 윤대협 능남고 197
'''# 실제 데이터 바로 반영이 필요 시, inplace=True
▷ Index 설정
# 지정한 column으로 Index 설정 : 객체.set_indxe('이름')
df = df.set_index('이름') # df.set_index('이름', inplace=True)
print(df)
'''
이름
채치수 북산고 197
정대만 북산고 184
송태섭 북산고 168
서태웅 북산고 187
강백호 북산고 188
변덕규 능남고 202
황태산 능남고 188
윤대협 능남고 197
'''
▷ Index 정렬
# Index 기준으로 오름차순, 내림차순 정렬
df = df.sort_index() # 오름차순 - 내림차순은 df.sort_index(ascending=True)
print(df)
'''
이름
강백호 북산고 188
변덕규 능남고 202
서태웅 북산고 187
송태섭 북산고 168
윤대협 능남고 197
정대만 북산고 184
채치수 북산고 197
황태산 능남고 188
'''
df.sort_index(ascending=False, inplace=True)
print(df)
'''
이름
황태산 능남고 188
채치수 북산고 197
정대만 북산고 184
윤대협 능남고 197
송태섭 북산고 168
서태웅 북산고 187
변덕규 능남고 202
강백호 북산고 188
'''
▣ 파일 저장 및 열기
# DataFrame 객체를 파일(excel, csv, txt 등)로 저장하거나, 파일로 불러온 후 DataFrame 객체를 만들기
data = {
'이름' : ['채치수', '정대만', '송태섭', '서태웅', '강백호', '변덕규', '황태산', '윤대협'],
'학교' : ['북산고', '북산고', '북산고', '북산고', '북산고', '능남고', '능남고', '능남고'],
'키' : [197, 184, 168, 187, 188, 202, 188, 197],
'국어' : [90, 40, 80, 40, 15, 80, 55, 100],
'영어' : [85,35, 75, 60, 20, 100, 65, 85],
'수학' : [100, 50, 70, 70, 10, 95, 45, 90],
'과학' : [95, 55, 80, 75, 35, 85, 40, 95],
'사회' : [85, 25, 75, 80, 10, 80, 35, 95],
'SW특기' : ['Python', 'Java', 'Javascript', '', '', 'C', 'PYTHON', 'C#']
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번', '7번', '8번'])
df.index.name = '지원번호'
print(df)
▷ csv 파일로 저장해보기
df.to_csv('./pandas/score.csv')
# 메모장 등으로 열면 정상적으로 보이지만 엑셀로 열면 한글이 깨짐
df.to_csv('./pandas/score.csv', encoding='utf-8-sig')
# 인덱스 부분을 제외해야 할 경우는
df.to_csv('./pandas/score.csv', encoding='utf-8-sig', index=False)
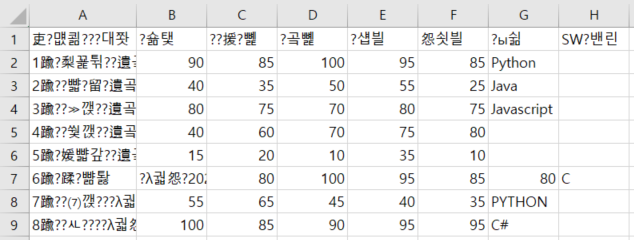
# 결과를 엑셀로 열면 한글이 깨져서 나온다. 메모장 등으로 열면 정상적으로 보이지만 엑셀로 열면 한글이 깨짐.
이를 해결하기 위해서는
df.to_csv('./pandas/score.csv', encoding='utf-8-sig') 처럼 수정해야 함
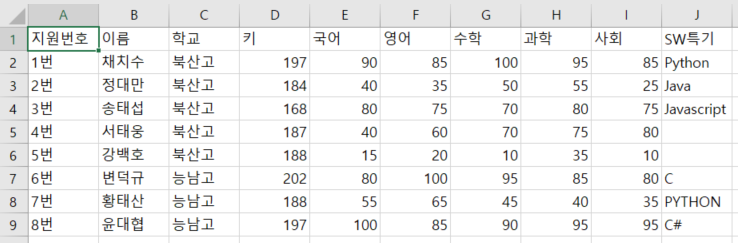
# 인덱스 부분을 제외해야 할 경우는
df.to_csv('./pandas/score.csv', encoding='utf-8-sig', index=False) 처럼 index=False로 한다.
▷ 텍스트(.txt) 파일로 저장해보기
df.to_csv('./pandas/score.txt', sep='\t') # tab으로 구분된 텍스트 파일로 저장
▷ 엑셀 파일로 저장해보기
df.to_excel('./pandas/score.xlsx')
▷ csv 파일 열기
df = pd.read_csv('./pandas/score.csv')
print(df)
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
0 채치수 북산고 197 90 85 100 95 85 Python
1 정대만 북산고 184 40 35 50 55 25 Java
2 송태섭 북산고 168 80 75 70 80 75 Javascript
3 서태웅 북산고 187 40 60 70 75 80 NaN
4 강백호 북산고 188 15 20 10 35 10 NaN
5 변덕규 능남고 202 80 100 95 85 80 C
6 황태산 능남고 188 55 65 45 40 35 PYTHON
7 윤대협 능남고 197 100 85 90 95 95 C#
'''
▷ row(행) 무시하고 가져오기
df = pd.read_csv('./pandas/score.csv', skiprows=1) # 지정된 갯수 만큼의 row를 건너뜀(1, theme 제외시킴)
print(df)
'''
채치수 북산고 197 90 85 100 95 85.1 Python
0 정대만 북산고 184 40 35 50 55 25 Java
1 송태섭 북산고 168 80 75 70 80 75 Javascript
2 서태웅 북산고 187 40 60 70 75 80 NaN
3 강백호 북산고 188 15 20 10 35 10 NaN
4 변덕규 능남고 202 80 100 95 85 80 C
5 황태산 능남고 188 55 65 45 40 35 PYTHON
6 윤대협 능남고 197 100 85 90 95 95 C#
'''
df = pd.read_csv('./pandas/score.csv', skiprows=[1,]) # 지정 row 제외 (1 제외)
print(df)
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
0 정대만 북산고 184 40 35 50 55 25 Java
1 송태섭 북산고 168 80 75 70 80 75 Javascript
2 서태웅 북산고 187 40 60 70 75 80 NaN
3 강백호 북산고 188 15 20 10 35 10 NaN
4 변덕규 능남고 202 80 100 95 85 80 C
5 황태산 능남고 188 55 65 45 40 35 PYTHON
6 윤대협 능남고 197 100 85 90 95 95 C#
'''
df = pd.read_csv('./pandas/score.csv', skiprows=[1, 3, 5]) # row 1,3,5 제외
print(df)
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
0 정대만 북산고 184 40 35 50 55 25 Java
1 서태웅 북산고 187 40 60 70 75 80 NaN
2 변덕규 능남고 202 80 100 95 85 80 C
3 황태산 능남고 188 55 65 45 40 35 PYTHON
4 윤대협 능남고 197 100 85 90 95 95 C#
'''
▷ 지정된 row(행) 개수만큼만 가져오기
df = pd.read_csv('./pandas/score.csv', nrows=4) # 지정된 갯수(4) row만 가져옴
print(df)
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
0 채치수 북산고 197 90 85 100 95 85 Python
1 정대만 북산고 184 40 35 50 55 25 Java
2 송태섭 북산고 168 80 75 70 80 75 Javascript
3 서태웅 북산고 187 40 60 70 75 80 NaN
'''
df = pd.read_csv('./pandas/score.csv', skiprows=2, nrows=2) # 처음 row 2개 무시하고, 이후 지정된 갯수(2) row만 가져옴
print(df)
'''
정대만 북산고 184 40 35 50 55 25 Java
0 송태섭 북산고 168 80 75 70 80 75 Javascript
1 서태웅 북산고 187 40 60 70 75 80 NaN
'''
▷ 텍스트(.txt) 파일 열기
df = pd.read_csv('./pandas/score.txt', sep='\t') # 구분자가 있을 경우 동일하게 해줌
print(df)
'''
지원번호 이름 학교 키 국어 영어 수학 과학 사회 SW특
기
0 1번 채치수 북산고 197 90 85 100 95 85 Python
1 2번 정대만 북산고 184 40 35 50 55 25 Java
2 3번 송태섭 북산고 168 80 75 70 80 75 Javascript
3 4번 서태웅 북산고 187 40 60 70 75 80 NaN
4 5번 강백호 북산고 188 15 20 10 35 10 NaN
5 6번 변덕규 능남고 202 80 100 95 85 80 C
6 7번 황태산 능남고 188 55 65 45 40 35 PYTHON
7 8번 윤대협 능남고 197 100 85 90 95 95 C#
'''
df = pd.read_csv('./pandas/score.txt', sep='\t', index_col='지원번호') # index 지정
print(df)
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
지원번호
1번 채치수 북산고 197 90 85 100 95 85 Python
2번 정대만 북산고 184 40 35 50 55 25 Java
3번 송태섭 북산고 168 80 75 70 80 75 Javascript
4번 서태웅 북산고 187 40 60 70 75 80 NaN
5번 강백호 북산고 188 15 20 10 35 10 NaN
6번 변덕규 능남고 202 80 100 95 85 80 C
7번 황태산 능남고 188 55 65 45 40 35 PYTHON
8번 윤대협 능남고 197 100 85 90 95 95 C#
'''
▷ 엑셀 파일 열기
df = pd.read_excel('./pandas/score.xlsx')
▣ DataFrame 데이터 확인
df = pd.read_excel('./pandas/score.xlsx', index_col='지원번호')
▷ DataFrame 확인 : df.describe()
# 계산을 할 수 있는 데이터에 대해 Column별로 데이터 갯수(count), 평균, 표준편차 최소, 최대값 등 표시
print(df.describe())
'''
키 국어 영어 수학 과학
사회
count 8.000000 8.000000 8.000000 8.000000 8.000000 8.000000
mean 188.875000 62.500000 65.625000 66.250000 70.000000 60.625000
std 10.480424 29.519969 26.917533 30.325614 23.754699 32.120032
min 168.000000 15.000000 20.000000 10.000000 35.000000 10.000000
25% 186.250000 40.000000 53.750000 48.750000 51.250000 32.500000
50% 188.000000 67.500000 70.000000 70.000000 77.500000 77.500000
75% 197.000000 82.500000 85.000000 91.250000 87.500000 81.250000
max 202.000000 100.000000 100.000000 100.000000 95.000000 95.000000
'''
▷ DataFrame 요약 정보 확인 : df.info()
print(df.info())
'''
<class 'pandas.core.frame.DataFrame'>
Index: 8 entries, 1번 to 8번
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 이름 8 non-null object
1 학교 8 non-null object
2 키 8 non-null int64
3 국어 8 non-null int64
4 영어 8 non-null int64
5 수학 8 non-null int64
6 과학 8 non-null int64
7 사회 8 non-null int64
8 SW특기 6 non-null object
dtypes: int64(6), object(3)
memory usage: 640.0+ bytes
None
'''
▷ df.head(n) : 처음 n개의 row 가져오기
# 디폴트는 5, df.head()
print(df.head(3))
'''
지원번호
1번 채치수 북산고 197 90 85 100 95 85 Python
2번 정대만 북산고 184 40 35 50 55 25 Java
3번 송태섭 북산고 168 80 75 70 80 75 Javascript
4번 서태웅 북산고 187 40 60 70 75 80 NaN
5번 강백호 북산고 188 15 20 10 35 10 NaN
'''
▷ df.tail(n) : 마지막에서부터 n개의 row 가져오기
# 디폴트는 5
▷ df.values : 값만 가져오기
print(df.values)
'''
[['채치수' '북산고' 197 90 85 100 95 85 'Python']
['정대만' '북산고' 184 40 35 50 55 25 'Java']
['송태섭' '북산고' 168 80 75 70 80 75 'Javascript']
['서태웅' '북산고' 187 40 60 70 75 80 nan]
['강백호' '북산고' 188 15 20 10 35 10 nan]
['변덕규' '능남고' 202 80 100 95 85 80 'C']
['황태산' '능남고' 188 55 65 45 40 35 'PYTHON']
['윤대협' '능남고' 197 100 85 90 95 95 'C#']]
'''
▷ df.columns : 전체 컬럼 확인
print(df.columns)
'''
Index(['이름', '학교', '키', '국어', '영어', '수학', '과학', '사회', 'SW특기
'], dtype='object')
'''
▷ df.shape : DataFrame의 크기
print(df.shape) # (8, 9)
▣ DataFrame의 Series 확인
print(df['키'])
'''
지원번호
1번 197
2번 184
3번 168
4번 187
5번 188
6번 202
7번 188
8번 197
Name: 키, dtype: int64
'''
print(df['키'].describe())
'''
count 8.000000
mean 188.875000
std 10.480424
min 168.000000
25% 186.250000
50% 188.000000
75% 197.000000
max 202.000000
Name: 키, dtype: float64
'''
print(df['키'].max()) # 202
# 최소값은 df['키'].min(), 평균은 df['키'].mean(), 합은 df['키'].sum()
print(df['SW특기'].count()) # 6, NaN은 제외
print(df['키'].nlargest(3)) # 키 큰 사람 순서대로 3명 데이터 가져오기
'''
지원번호
6번 202
1번 197
8번 197
Name: 키, dtype: int64
'''
# 중복 제외
print(df['학교'].unique()) # ['북산고' '능남고']
# 중복 제외하고 학교의 수
print(df['학교'].nunique()) # 2
▣ DataFrame 데이터 선택
▶ 데이터 선택(기본)
df = pd.read_excel('./pandas/score.xlsx', index_col='지원번호')
print(df)
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
지원번호
1번 채치수 북산고 197 90 85 100 95 85 Python
2번 정대만 북산고 184 40 35 50 55 25 Java
3번 송태섭 북산고 168 80 75 70 80 75 Javascript
4번 서태웅 북산고 187 40 60 70 75 80 NaN
5번 강백호 북산고 188 15 20 10 35 10 NaN
6번 변덕규 능남고 202 80 100 95 85 80 C
7번 황태산 능남고 188 55 65 45 40 35 PYTHON
8번 윤대협 능남고 197 100 85 90 95 95 C#
'''
▷ Column 선택(label) : 원하는 컬럼 선택 : df['label']
print(df['이름'])
'''
지원번호
1번 채치수
2번 정대만
3번 송태섭
4번 서태웅
5번 강백호
6번 변덕규
7번 황태산
8번 윤대협
Name: 이름, dtype: object
'''
print(df[['이름', '키']])
'''
지원번호
1번 채치수 197
2번 정대만 184
3번 송태섭 168
4번 서태웅 187
5번 강백호 188
6번 변덕규 202
7번 황태산 188
8번 윤대협 197
'''
▷ Column 선택(정수 index) : 원하는 컬럼 index 0 ~ n
print(df.columns)
# Index(['이름', '학교', '키', '국어', '영어', '수학', '과학', '사회', 'SW특기'], dtype='object')
print(df.columns[0])
# 이름
print(df[df.columns[0]]) # df['이름'] 동작과 동일
'''
지원번호
1번 채치수
2번 정대만
3번 송태섭
4번 서태웅
5번 강백호
6번 변덕규
7번 황태산
8번 윤대협
Name: 이름, dtype: object
'''
print(df[df.columns[-1]]) # 맨 우측 마지막
'''
지원번호
1번 Python
2번 Java
3번 Javascript
4번 NaN
5번 NaN
6번 C
7번 PYTHON
8번 C#
Name: SW특기, dtype: object
'''
▷ 슬라이싱
print(df['영어'][0:5])
# 0 ~ 4까지 영어 점수 데이터 가져옴
'''
지원번호
1번 85
2번 35
3번 75
4번 60
5번 20
Name: 영어, dtype: int64
'''
print(df[['이름', '키']][:3])
# 처음 3명의 이름, 키 정보를 가져옴
'''
이름 키
지원번호
1번 채치수 197
2번 정대만 184
3번 송태섭 168
'''
print(df[3:7])
# 전체 데이터에서 지정한 슬라이싱 데이터(4번째에서 7번째까지)만 가져옴
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
지원번호
4번 서태웅 북산고 187 40 60 70 75 80 NaN
5번 강백호 북산고 188 15 20 10 35 10 NaN
6번 변덕규 능남고 202 80 100 95 85 80 C
7번 황태산 능남고 188 55 65 45 40 35 PYTHON
'''
▶ 데이터 선택(loc)
- loc : location
- 이름을 이용하여 원하는 row에서 원하는 col 선택
- 일반적인 슬라이싱의 index 0 ~ n이지만, df.loc[]에서는 실제 데이터 기준의 index를 기준으로 한다는 점에 주의!
▷ df.loc['row 이름']
print(df.loc['1번']) # index 1번에 해당하는 전체 데이터 가져옴
'''
이름 채치수
학교 북산고
키 197
국어 90
영어 85
수학 100
과학 95
사회 85
SW특기 Python
Name: 1번, dtype: object
'''# 지정한 row 이름이 없으면 KeyError 발생
▷ df.loc['row 이름', 'col 이름'] : 일부 col만 가져오기
print(df.loc['5번', '영어']) # index 2번의 영어 성적
# 20
print(df.loc[['1번', '2번'], '영어'])
# 1번과 2번의 영어 성적 가져옴. row 이름을 여러개 지정
'''
지원번호
1번 85
2번 35
Name: 영어, dtype: int64
'''
print(df.loc[['1번', '3번'], ['영어', '수학']])
# 1번과 3번의 영어, 수학 성적 가져옴. row 이름과 col 이름을 여러개 지정
'''
영어 수학
지원번호
1번 85 100
3번 75 70
'''
▷ 슬라이싱 응용 - 대괄호는 하나만 사용
print(df.loc['1번':'5번', '국어':'사회'])
# index 1번부터 5번까지, 국어부터 사회까지 데이터
'''
국어 영어 수학 과학 사회
지원번호
1번 90 85 100 95 85
2번 40 35 50 55 25
3번 80 75 70 80 75
4번 40 60 70 75 80
5번 15 20 10 35 10
'''# 일반적인 슬라이싱의 index 0 ~ 4이지만, df.loc[]에서는 실제 데이터 기준의 index를 기준으로 한다는 점에 주의!
▶ 데이터 선택(iloc)
- i는 integer
- 위치를 이용하여 원하는 row에서 원하는 col 선택
▷ df.iloc[index number]
print(df.iloc[5]) # index 5 (6번) 전체 데이터 가져옴
'''
이름 변덕규
학교 능남고
키 202
국어 80
영어 100
수학 95
과학 85
사회 80
SW특기 C
Name: 6번, dtype: object
'''
print(df.iloc[4:6]) # index 4 ~ 5
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
지원번호
5번 강백호 북산고 188 15 20 10 35 10 NaN
6번 변덕규 능남고 202 80 100 95 85 80 C
'''
print(df.iloc[0, 1])
# row index 0 위치의 col indxe 1 (학교)의 데이터
# 북산고
print(df.iloc[[0, 1], 2])
# row index 0, 1의 col index 2 (키) 데이터
'''
지원번호
1번 197
2번 184
Name: 키, dtype: int64
'''
print(df.iloc[[0, 1], [0, 1, 2]])
'''
이름 학교 키
지원번호
1번 채치수 북산고 197
2번 정대만 북산고 184
'''
▷ 슬라이싱
위 2개 예시와 동일한 데이터를 추출해보면,
print(df.iloc[0:2, 2])
'''
지원번호
1번 197
2번 184
Name: 키, dtype: int64
'''
print(df.iloc[0:2, 0:3])
'''
이름 학교 키
지원번호
1번 채치수 북산고 197
2번 정대만 북산고 184
'''
▶ 데이터 선택 (조건)
▷ 주어진 어떤 조건에 해당하는 데이터 선택하여 추출하기
print(df['키'] >= 185)
# 키가 185 이상인지 여부를 True/False로 표시
'''
지원번호
1번 True
2번 False
3번 False
4번 True
5번 True
6번 True
7번 True
8번 True
Name: 키, dtype: bool
'''
▷ 조건 활용 : filter 기능
filt = (df['키'] >= 185)
print(df[filt])
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
지원번호
1번 채치수 북산고 197 90 85 100 95 85 Python
4번 서태웅 북산고 187 40 60 70 75 80 NaN
5번 강백호 북산고 188 15 20 10 35 10 NaN
6번 변덕규 능남고 202 80 100 95 85 80 C
7번 황태산 능남고 188 55 65 45 40 35 PYTHON
8번 윤대협 능남고 197 100 85 90 95 95 C#
'''
# filter 조건 직접 적용하고 싶으면, print(df[df['키'] >= 185])
print(df[-filt])
# 반대인 경우를 추출하고 싶을 때는 filt를 역으로 적용
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
지원번호
2번 정대만 북산고 184 40 35 50 55 25 Java
3번 송태섭 북산고 168 80 75 70 80 75 Javascript
'''
▷ loc와 복합 사용 : df.loc[row_sel, col_sel]
print(df.loc[df['키'] >= 185, '영어']) # filter 조건 직접 적용
'''
지원번호
1번 85
4번 60
5번 20
6번 100
7번 65
8번 85
Name: 영어, dtype: int64
'''
print(df.loc[df['키'] >= 185, ['이름', '영어', '수학']])
'''
이름 영어 수학
지원번호
1번 채치수 85 100
4번 서태웅 60 70
5번 강백호 20 10
6번 변덕규 100 95
7번 황태산 65 45
8번 윤대협 85 90
'''
▷ 다양한 조건 : & (그리고), | (또는)
# & 그리고
# print(df.loc[df['키'] >= 185 & df['학교'] == '북산고']) # 조건을 괄호로 묶어줘야 에러 안남
print(df.loc[(df['키'] >= 185) & (df['학교'] == '북산고')])
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
지원번호
1번 채치수 북산고 197 90 85 100 95 85 Python
4번 서태웅 북산고 187 40 60 70 75 80 NaN
5번 강백호 북산고 188 15 20 10 35 10 NaN
'''
# | 또는
print(df.loc[(df['키'] < 170) | (df['키'] > 200)])
'''
이름 학교 키 국어 영어 수학 과학 사회 SW특기
지원번호
3번 송태섭 북산고 168 80 75 70 80 75 Javascript
6번 변덕규 능남고 202 80 100 95 85 80 C
'''
[관련 자료 더보기]
[출처] 파이썬 코딩 무료 강의 (활용편5) - 데이터 분석 및 시각화, 이 영상 하나로 끝내세요

블로그 인기글
엑셀 시트 분리 저장 - 엑셀 파일의 시트를 분리하여 저장하기
엑셀을 사용하다 보면 엑셀 시트를 분리해서 저장해야 할 때가 있다. 최근에도 이런 경우가 발생하여 구글링 후 엑셀 시트 분리 업무를 수행하고 내친김에 다른 사람들도 사용할 수 있도록 파이썬 tkinter로 프로그램으로 만들어 보았다. Excel Sheets 분리 저장하는 프로그램(with 파이썬 Tkinter) ※ 프로그램 다운로드(네이버 MYBOX에서 공유) : ExcelSeparateSheets.zip ▶ 프래그램을 실행하면 다음과 같이 초기 화면이 보인다. 찾아보기 : 엑셀 파일이 있는 폴더를 선택한다. (프로그램이 있는 최상위 디렉터리가 열린다) 실행하기 : 프로그램 실행 버튼 상태 변경 순서 : 실행전 → 실행 중 → Sheet "OOO" 분리 저장 중 → 실행 완료 실행 결과 확인 : 엑셀 파..
goodthings4me.tistory.com
[엑셀] 근무연수 및 근무 개월수 계산하는 함수
직장을 다니다 보면 몇 년 몇 개월 또는 전체 며칠을 다니고 있는지 궁금할 때가 있다. 아니면, 총무나 인사 일을 할 때 직원들의 근속연수 또는 근속개월수 등을 계산하고 싶을 때도 있다. 이런 경우 엑셀 함수를 활용하면 어떨까!! 근무연수 및 근무 개월수 계산 함수 알아보기 엑셀에서 근무연수 또는 근무 개월수 계산하는 것은 datedif() 함수를 사용하면 간단하게 해결할 수 있다. 아래 이미지를 보면서 설명하면, 셀 E1에 기준일자를 입력하고, 근무연수를 구할 때는 =datedif(B3,$E$1,"Y")&"년" 을 입력한다. 근무개월수는 =datedif(B3,$E$1,"M")&"개월" 처럼 입력한다. 일수까지 파악할 때문 별로 없지만, 심심풀이로 구해보고 싶을 때 =datedif(B3,$E$1,"D")..
goodthings4me.tistory.com
Windows 10 탐색기 느려지는 증상과 해결하는 방법
잘 작동하던 Windows 10 탐색기가 갑자기 느려지는 증상이 발생했을 때 어떻게 조치를 하는지 구글에서 찾아보니 많은 해결책들이 있었으나 어떤 것이 정확한 해결책인지는 알 수가 없었다. 그래서 해결방법이라고 제시한 것들을 정리해 보았다. 윈도우 탐색기가 느려지는 증상 해결 방법 어느 순간부터 응용프로그램(VS Code 등)에서 폴더 열기나 파일 불러오기를 했을 때 검색 팝업창이 안 뜨거나 열리는 시간이 엄청 느려지는 증상과, 더불어서 탐색기도 실행이 많이 느려지는 증상이 있었다. 기존에 사용하던 VS Code에 openpyxl 설치 후 실행이 느려지는 증상이 발생하더니 윈도우10 탐색기도 느려져서 사용할 수가 없었다. 노트북에 OS(Windows10)를 설치한지 1년이 다 되어가긴 했지만, 1개월 전..
goodthings4me.tistory.com
'코딩 연습' 카테고리의 다른 글
| 공동주택 단지코드(아파트 코드) 추출 - 파이썬 API 활용 (0) | 2022.11.30 |
|---|---|
| 엑셀 암호 해제 방법 - 파이썬으로 엑셀 암호 제거 프로그램 만들기 (0) | 2022.10.13 |
| 엑셀 시트 분리 저장 - 엑셀 파일의 시트를 분리하여 저장하기 (2) | 2022.09.25 |
| 유튜브 음원 추출 다운로드(유뷰브 음악 추출하는 2가지 방법) (0) | 2022.09.19 |
| 유뷰트 영상 다운로드 - 파이썬 tkinter (0) | 2022.09.13 |




댓글