
goodthings4me.tistory.com
파이썬으로 이미지 다운로드 관련 코딩을 할 때, 동적인 페이지의 문제로 인해 selenium을 많이 사용한다. 그러나 selenium의 단점으로 인해 다른 방법을 찾는 것이 사실인데, 이런 부분을 requests-html로 어느 정도 해결이 되는 것 같아서 다음 이미지 다운로드 방법으로 requests와 requests_html를 비교해본다.
Daum 이미지 다운로드 관련 requests와 requests-html 중 무엇을 사용할 것인가

- 다음에서 이미지만 보여주는 탭에서 최근 화두인 '메타버스' 이미지 검색
- 이미지 링크 주소(URL)가 잘 보인다. requests.get()으로 다운로드 가능할까?
- 첫 번째 이미지 소스코드중 https://search4.kakaocdn.net/argon/0x200_85_hr/9H2AVOynrIU 부분을 검색한 결과, 보이긴 하는데, 메모장(아래 이미지)에 옮겨서 보니 html 코드가 아니었다. 상단으로 더 올려 보면 <javascript> 부분이 있음.
requests.get() 사용한 경우
import requests
from bs4 import BeautifulSoup
keyword = '메타버스'
url = f'https://search.daum.net/search?w=img&q={keyword}&DA=IIM'
r1 = requests.get(url)
soup = BeautifulSoup(r1.text, 'html.parser')
imgList = soup.find('div', id='imgList')
print(imgList)
# <div class="cont_img cont_tab" id="imgList"> </div>
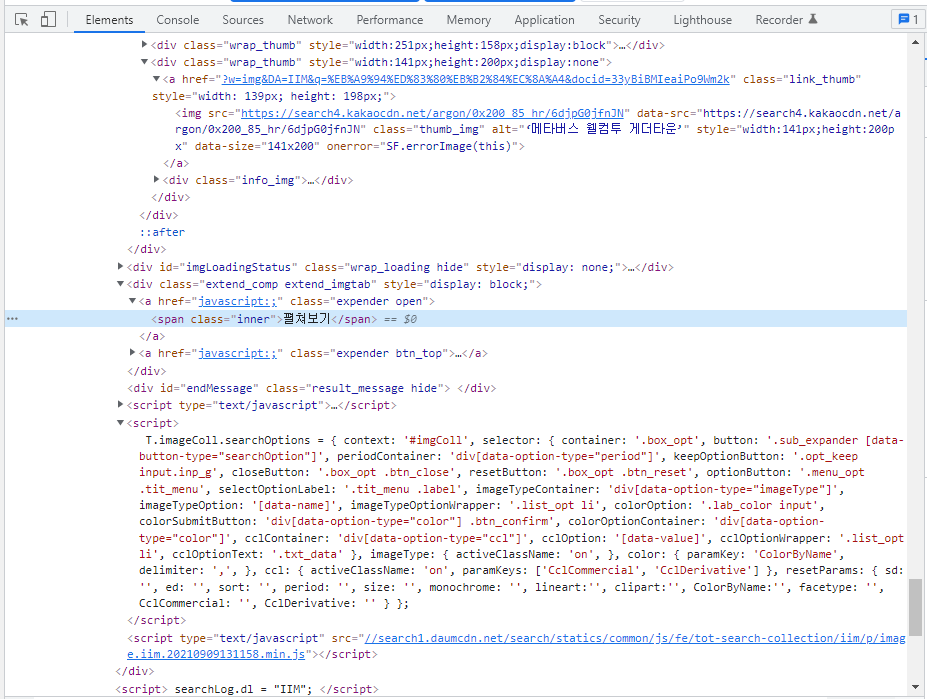
img_list = imgList.find_all('div', {'class':'wrap_thumb'})
print(len(img_list)) # 0- 데이터를 불러오지 못한다.
requests_html의 HTMLSession() 사용한 경우
from requests_html import HTMLSession
keyword = '메타버스'
url = f'https://search.daum.net/search?w=img&q={keyword}&DA=IIM'
session = HTMLSession()
r = session.get(url)
# r.html.render()
imgList = r.html.find('div#imgList')
print(type(imgList), len(imgList))
# <class 'list'> 1
print(imgList[0])
# <Element 'div' id='imgList' class=('cont_img', 'cont_tab')>
print(imgList[0].html)
# <div id="imgList" class="cont_img cont_tab"> </div>
print(imgList[0].text) # ''
img_list = r.html.find('div#imgList > div.wrap_thumb > a > img')
print(len(img_list)) # 0
img_list = imgList[0].find('div.wrap_thumb > a > img')
print(len(img_list)) # 0- imgList[0]과 imgList[0].html은 값을 불러왔으나, imgList[0].text는 데이터가 없다
- 하위 요소(div.wrap_thumb > a > img) 또한 데이터를 불러오지 못한다.
아래 코드블럭을 보면, JavaScript 렌더링 기능을 통해 왜 requests_html이 "Full JavaScript support!"이라고 하는지 알 수 있다.
from requests_html import HTMLSession
keyword = '메타버스'
url = f'https://search.daum.net/search?w=img&q={keyword}&DA=IIM'
session = HTMLSession()
r = session.get(url)
r.html.render()
imgList = r.html.find('div#imgList')
print(type(imgList), len(imgList))
# <class 'list'> 1
print(imgList[0])
# <Element 'div' id='imgList' class=('cont_img', 'cont_tab') style='width: 1129px;'>
print(imgList[0].html)
'''
<Element 'div' id='imgList' class=('cont_img', 'cont_tab') style='width: 1129px;'>
<div id="imgList" class="cont_img cont_tab" style="width: 1129px;"> <div class="wrap_thumb" style="width:296px;height:168px;display:block">
<a href="?w=img&DA=IIM&q=%EB%A9%94%ED%83%80%EB%B2%84%EC%8A%A4&docid=33UvSdma4tW5r0wcpg" class="link_thumb">
<img src="https://search4.kakaocdn.net/argon/0x200_85_hr/9H2AVOynrIU" data-src="https://search4.kakaocdn.net/argon/0x200_85_hr/9H2AVOynrIU" class="thumb_img" alt="메타버스 Metaverse" style="width:299px;height:168px;margin-left:-1px" data-size="296x168" onerror="SF.errorImage(this)"/>
</a>
<div class="info_img">
<a href="javascript:;" class="link_info" title="메타버스 Metaverse">
<strong class="tit_img"><b>메타버스</b> Metaverse</strong> ....
'''
print(imgList[0].text)
'''
메타버스 Metaverse 블로그
원본
메타버스 관련주 블로그
원본
'Z세대 흐름' 메타버스 읽는 사람들..미래 지향 전망서 인기 2021.10.26
원본
메타버스 블로그
원본 ....
'''
img_list = r.html.find('div#imgList > div.wrap_thumb > a > img')
print(len(img_list)) # 80
img_list = imgList[0].find('div.wrap_thumb > a > img')
print(len(img_list)) # 80
for img in img_list:
img_src = img.attrs['src']
alt = img.attrs['alt']
print(img_src, alt)
'''
https://search4.kakaocdn.net/argon/0x200_85_hr/9H2AVOynrIU 메타버스 Metaverse
https://search3.kakaocdn.net/argon/0x200_85_hr/8sN9XZ1WiE1 메타버스 관련주
https://search3.kakaocdn.net/argon/0x200_85_hr/EpuqnF1p3xC 'Z세대 흐름' 메타
버스 읽는 사람들..미래 지향 전망서 인기
https://search4.kakaocdn.net/argon/0x200_85_hr/9NzYTXoutoN 메타버스
https://search4.kakaocdn.net/argon/0x200_85_hr/3XZqcyEQlmy 메타버스 뜻
https://search4.kakaocdn.net/argon/0x200_85_hr/2VECAiHgHF3 메타버스의 기본개념과 종류를
알아보자. 증강현실. 라이프로깅.
https://search3.kakaocdn.net/argon/0x200_85_hr/F4kbRJkw8T3 메타버스 Metaverse
https://search4.kakaocdn.net/argon/0x200_85_hr/3V7f8yxoz8Z 한화시스템, 메타버스 플랫폼
에서 신입·경력 개발자 면접 ....
'''- r.html.render() 한 문장 추가한 것 뿐인데, 데이터를 모두 가져온 것을 볼 수 있다.

이제, 이미지 원본을 가지러 가볼 것이다.
r1.html.find('div#imgList > div.wrap_thumb > a')
print(len(img_list)) # 80- img 태그 바로 위 a 태그에 링크된 주소가 원본 이미지를 보여주는 페이지인데, 문제는 펼침으로 이미지를 보여주기 때문에 그 페이지에서 다시 원본 링크를 찾아야 한다.
- 메타버스 관련 이미지 80개 나온 img_list가 리스트 타입이기 때문에 for 문으로 확인을 해보면, 별도의 <img src=....> 태그로 이미지가 링크되어 있다.
Daum 이미지 다운로드 소스 코드
from requests_html import HTMLSession
from urllib.parse import urljoin
import os
def daumImage_scraping(keyword):
url = f'https://search.daum.net/search?w=img&q={keyword}&DA=IIM'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
session = HTMLSession()
r1 = session.get(url, headers=headers)
r1.html.render()
# print(r1.text)
# print(r1.html.html) # 렌더링 부분을 html로 확인할 경우
# ## 스크롤을 하고 싶다면...
# r1.html.render(scrolldown=5000) # scrolldown value = pixel
img_list = r1.html.find('div#imgList > div.wrap_thumb > a')
print(len(img_list)) # 80
if not os.path.exists('daum_images'):
os.mkdir('daum_images')
imgCount = 1
for img in img_list:
img_src = img.attrs['href']
img_src = urljoin(url, img_src)
# print(img_src)
r2 = session.get(img_src, headers=headers)
r2.html.render()
# print(r2.html.html)
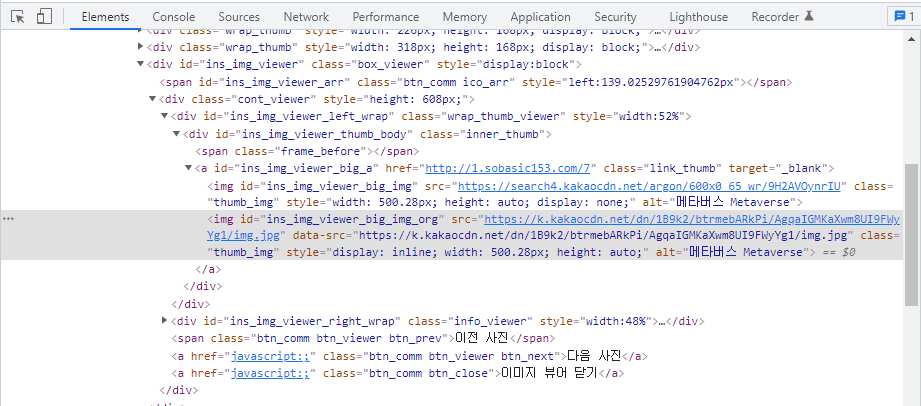
img_res = r2.html.find('#ins_img_viewer_big_img_org')
# print(len(img_res)) # 1
img_url = img_res[0].attrs["src"]
print(img_url)
file_name = str(imgCount).zfill(3) + '_' + img_url.split('/')[-1]
print(file_name)
imgCount += 1
## 이미지 다운로드
with open('./daum_images/' + file_name, 'wb') as f:
f.write(session.get(img_url, headers=headers).content)
if imgCount > 10:
break
daumImage_scraping('메타버스')- for 문으로 한 번에 다운로드 가능한 이미지는 80개인데, 이미지 스크롤을 하고 싶다면, scrolldown= 속성을 주어서 스크롤을 내릴 수 있다.
- r1.html.render(scrolldown=5000) 코드로 스크롤 후 확인해보니 320개까지 찾아준다.
- 그리고, 그 이후는 '펼쳐보기' 버튼이 있다.
- 이 부분에 대해서는 자료를 찾아보아야 해결 여부를 판단할 수 있을 것 같다. (찾으면 내용 추가..)
주의할 것은,
각각의 이미지에도 경고문구가 있듯이 이미지는 저작권 문제가 있으니 항상 주의하고,
무리한 이미지 다운로드는 서버에 악영향을 준다는 점,
그로 인해 다른 문제(?)도 발생할 수 있으니 스크래핑(크롤링)은 항상 조심을 해야....
블로그 인기글
엑셀 시트 분리 저장 - 엑셀 파일의 시트를 분리하여 저장하기
엑셀을 사용하다 보면 엑셀 시트를 분리해서 저장해야 할 때가 있다. 최근에도 이런 경우가 발생하여 구글링 후 엑셀 시트 분리 업무를 수행하고 내친김에 다른 사람들도 사용할 수 있도록 파이썬 tkinter로 프로그램으로 만들어 보았다. Excel Sheets 분리 저장하는 프로그램(with 파이썬 Tkinter) ※ 프로그램 다운로드(네이버 MYBOX에서 공유) : ExcelSeparateSheets.zip ▶ 프래그램을 실행하면 다음과 같이 초기 화면이 보인다. 찾아보기 : 엑셀 파일이 있는 폴더를 선택한다. (프로그램이 있는 최상위 디렉터리가 열린다) 실행하기 : 프로그램 실행 버튼 상태 변경 순서 : 실행전 → 실행 중 → Sheet "OOO" 분리 저장 중 → 실행 완료 실행 결과 확인 : 엑셀 파..
goodthings4me.tistory.com
[국세청] 현금영수증가맹점으로 가입바랍니다. 메시지 해결방법(개인사업자)
▶ 현금영수증 가맹점 가입 메시지를 받고... 온라인 쇼핑몰 사업을 시작하려고 사업자등록증을 발급받고 난 후 얼마 안 있어서 국세청으로부터 어느 시점까지 '현금영수증 가맹점'으로 가입하라는 문자메시지가 받았었다. 그 메시지 기한이 오늘 도래했는데, 인터넷에서 찾아보니 홈택스에서 현금영수증 발급 사업자 신청을 할 수가 있었다. [관련내용] 홈>국세정책/제도>전자(세금)계산서/현금영수증/신용카드>현금영수증∙신용카드>가맹점가입 ▶ 홈택스 사이트에서 신청하는 절차는 다음과 같다. 우선, 홈택스에 로그인을 해야 합니다. 세상이 좋아져서 공인인증서 없이도 손쉽게 간편인증 로그인이 가능하다. 여러 인증방법 중 카카오톡 인증이 가장 편리한 거 같다. 간편인증 로그인 후 상단 '조회/발급' 탭 클릭 후 '현금영수증>현금..
goodthings4me.tistory.com
유튜브 영상 등의 URL 주소를 QR코드로 만들기
네이버 QR코드, makeQR, MUST QRcode, 무료 온라인 QRCode 생성기 등의 웹사이트에서 유튜브 영상 등의 URL을 입력하여 QR코드를 만들 수 있다. QR코드를 생성할 수 있는 사이트와 프로그램 URL 주소를 붙여넣기 한 후 "QR 코드 생성" 버튼을 클릭하면 큐알코드가 이미지로 생성되고, 다운로드도 할 수 있는 사이트 https://truedoum.com/useful/qrcode/ # 유튜브에서 동영상 URL을 복사하는 방법 유튜브에서 QR코드를 만들 동영상을 검색한다. 해당 동영상을 클릭한다. 동영상 위에서 마우스 우클릭 후 나오는 팝업창에서 “동영상 URL 복사”를 클릭하거나 영상 하단의 “공유”를 클릭하여 나온 창에서 URL를 복사한다. 아래의 웹사이트 중 하나를 선택한 후 복사..
goodthings4me.tistory.com
'코딩 연습 > 코딩배우기' 카테고리의 다른 글
| 웹 페이지 <script> 태그 CDATA, 넌 뭐하는 넘이니... (0) | 2022.01.15 |
|---|---|
| 네이버 쇼핑 아이디별 등록 상품 추출하는 법(파이썬 script 태그 스크래핑 가이드) (3) | 2022.01.14 |
| 동적(JavaScript) 웹 페이지의 json 데이터 형식 이미지 다운로드 (with 파이썬) (0) | 2022.01.11 |
| 11번가 실시간 쇼핑 검색어 추출해서 저장하기(python tkinter) (0) | 2022.01.10 |
| 단축 URL 스크래핑에 파이썬 비동기 처리 개념 적용해보기 (0) | 2022.01.07 |




댓글