
goodthings4me.tistory.com
네이버 뉴스 페이지 하단에 있는 감정 표시 '좋아요, 훈훈해요, 슬퍼요, 화나요, 후속기사원해요'에 대한 숫자를 추출할 때 requests-html 모듈을 활용해서 크롤링을 해왔다.
네이버 뉴스 감정 표시 숫자에 대한 파이썬 크롤링
개발자 도구(F12)에서는 숫자 값이 보이지만 data-type이나 data-log를 보니 js로 처리되는 것으로 보인다.
바로 위 <script>에서 확인.
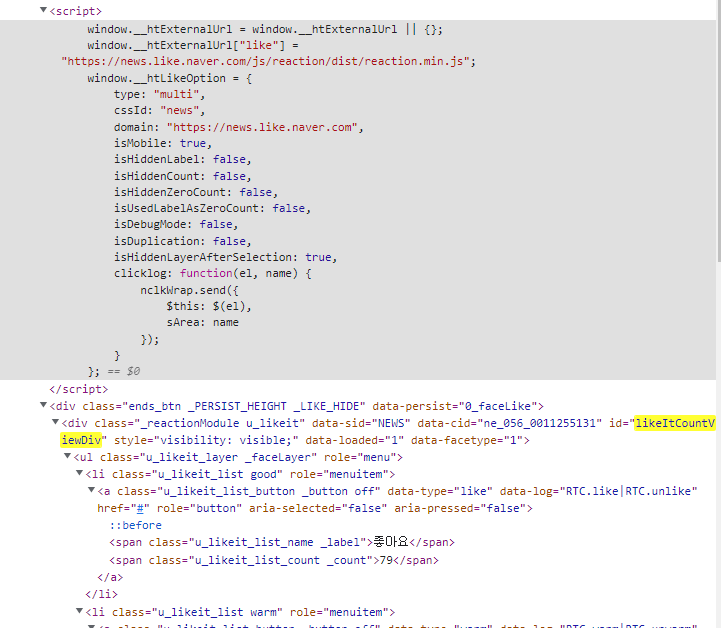
이런 경우, 페이지 소스 보기로는 숫자가 보이지 않는다. 이렇게 동적인 페이지에 대해 크롤링 시 selenium을 사용하는데... 이번에는 다른 방법으로 해보았다.

[파이썬 소스 코드]
from bs4 import BeautifulSoup
import time
from requests_html import HTMLSession
headers = {
'user_agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
}
url = 'https://n.news.naver.com/article/056/0011255131?ntype=RANKING'
s = HTMLSession()
r = s.get(url, headers=headers)
time.sleep(2)
if r.ok:
r.html.render(sleep=1)
# print(r.html.html)
soup = BeautifulSoup(r.html.html, 'html.parser')
rtcs = soup.select('#likeItCountViewDiv > ul > li')
for rtc in rtcs:
print(rtc.find('span', class_='u_likeit_list_name').text)
print(rtc.find('span', class_='u_likeit_list_count').text)- requests_html 모듈 설치 : pip install requests-html
- 위 코드처럼 javascript 렌더링을 하면 <script>태그 부분이 보일 수 있다.
- 본 코드도 requests_html 모듈을 사용해보니 추출이 가능했다.

[실행 결과]
좋아요
79
훈훈해요
28
슬퍼요
9
화나요
1,419
후속기사원해요
36
실시간 검색어 찾아주는 프로그램 - 파이썬 Tkinter, pyinstaller 모듈 사용
네이버 실검이라는 말이 없어진 지 수년... 네이버 실시간 검색어 기능이 폐지된 이후, 현재 실시간 인기 검색어 1위는 무엇일까? 궁금할 때마다 네이트나 줌(zum) 서비스를 통해
goodthings4me.tistory.com
'코딩 연습 > 파이썬 크롤링' 카테고리의 다른 글
| 네이버 뉴스 크롤링 - 기사 제목과 링크(URL) 추출 (0) | 2022.05.16 |
|---|---|
| 티스토리 블로그 내 이미지 다운로드 (0) | 2022.05.10 |
| 네이트 실시간검색어 (0) | 2022.04.25 |
| 크롤링 - 교보문고 도서 리스트 추출하기 (0) | 2022.04.22 |
| 스마트스토어 상품 리뷰 추출하기 - 파이썬 크롤링 연습 (2) | 2022.04.15 |




댓글