
goodthings4me.tistory.com
네이버 쇼핑의 각 판매자 사이트에 들어가 보면 상품 리스트가 있고, 각 상품에 대한 제목, 가격, 리뷰수, 평점 등의 데이터가 있다. 이 부분을 확인해보면 <script> 태그 부분으로 되어있는데, 파이썬으로 이 부분을 스크래핑(크롤링)하는 방법을 설명하고자 한다.
파이썬 requests로 네이버쇼핑 아이디별 등록 상품 리스트 데이터 추출
네이버 쇼핑에서 상품 검색 시 스마트스토어에 상품을 등록한 판매자명이 보인다.
그 부분을 클릭하면 해당 판매자의 스마트스토어 쇼핑몰에 접속하게 되는데, 상품 리스트의 html 소스코드 내용을 보기 위해 "페이지 소스보기"를 해서 보던지, "개발자 도구(F12)"를 펼쳐 Name에서 메인 화면 또는 특정 항목(판매자 ID 등)으로 된 부분을 클릭해서 Response 부분의 코드를 보면 <script> 부분 밑에 관련 정보가 있는 것을 발견하게 된다.
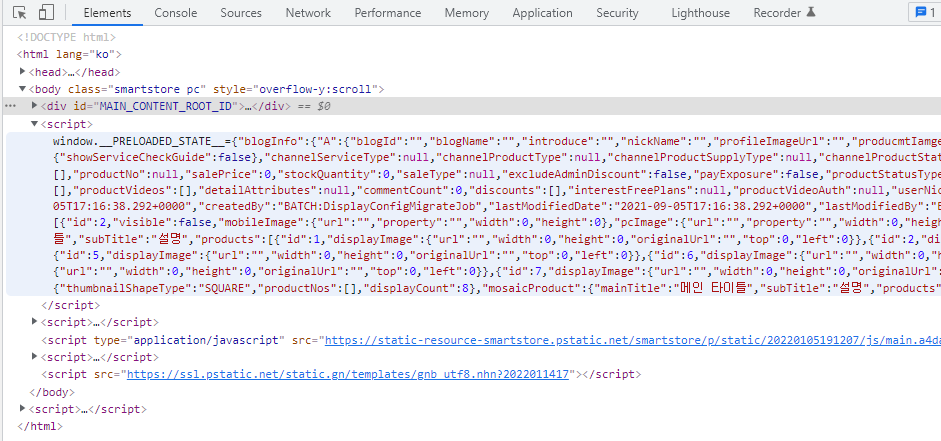
<script>window.__PRELOADED_STATE__={"blogInfo":{"A":{"blogId":"","blogName" 부분으로 된 부분이 해당 판매자 쇼핑몰의 데이터들이 있는 태그이다.
import requests
from bs4 import BeautifulSoup
uid = '쇼핑 ID'
url = f'https://smartstore.naver.com/{uid}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
r1 = requests.get(url, headers=headers)
if r1.status_code == 200:
soup = BeautifulSoup(r1.text, 'html.parser')
scripts = soup.find('body').find_all('script')
print(len(scripts))
cnt = 0
for script in scripts:
print(f'cnt: {cnt}:\n{script.text}')
cnt += 1- script 태그를 requets와 BeautifulSoup로 파싱한 후 script 태그가 몇 개 있고, 몇 번째가 대상인지 확인하기 위한 코드이다.
- 그리고, 네이버이다 보니 headers 정보는 필히 넣어준다.
출력된 부분을 확인해보면 json 형식의 str 타입인데, window.__PRELOADED_STATE__= 부분을 삭제하기 위해 아래처럼 slice를 해준다.
data = scripts[0].text.strip()[27:]
print(data[:200])
print('--------------------------')
print(data[-100:])- print(data[]) 부분은 잘 제거되었는지 확인하는 코드이다.
그런데, 잘 제거해졌다고 믿고 json()으로 str 전체를 불러오려고 했을 때, 오류가 발생했다.
json.decoder.JSONDecodeError: Expecting value: line 1 column 201 (char 200)- decoder 문제인데, 구글에서 찾아보고 여러 방법을 시도했지만, 오류는 계속 발생했다.

저장해서 텍스트 파일을 열어봐도 문제는 없어 보였는데, 눈에 거슬리는 문자(🧡 💙 💚 💜 ❤)가 보였다.
with open('./data.txt', 'w', encoding='utf-8', errors='ignore') as f:
f.write(data)
얼마 전에 이런 이모지 문자로 인해 어려움을 겪은 것이 떠올라서 해당 소스에서 이모지 문자를 제거하는 함수를 가져와서 추출된 data를 넣고 실행 후 리턴 값을 받아서 처리해봤다.
def remove_emoji(data):
emoj = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002500-\U00002BEF" # chinese char
u"\U00002702-\U000027B0"
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
u"\U0001f926-\U0001f937"
u"\U00010000-\U0010ffff"
u"\u2640-\u2642"
u"\u2600-\u2B55"
u"\u200d"
u"\u23cf"
u"\u23e9"
u"\u231a"
u"\ufe0f" # dingbats
u"\u3030"
"]+", re.UNICODE)
return re.sub(emoj, '', data)
data = remove_emoji(data) # 이모지 제거
r2 = json.loads(data)
print(r2, type(r2)) # <class 'dict'>- 이제 제대로 실행이 되었다. 문제가 된 부분이 바로 이것 떄문이었다.
추출된 data에서 "상품 전체" 부분만을 다시 정제하기 위해 json 포맷을 확인하는 사이트(https://jsonformatter.curiousconcept.com/)에서 돌려보니 아래와 같이 복잡한 구조로 되어있음을 확인했다.


- 이 구조에서 어디 부분이 '상품 전체"인지 찾아보니 widgetContents 부분에 있었다.
dict 데이터에서 그 부분을 아래와 같이 for 문으로 필요한 부분만을 추출했다.
r2 = json.loads(data)
# print(r2, type(r2)) # <class 'dict'>
item_cnt = 0
itemsList =[]
for dict_elem in r2['widgetContents']['wholeProductWidget']['A']['data']: # 상품전체 부분을 대상으로 함
name = dict_elem['name']
items ={
'name': dict_elem['name'],
'id': dict_elem['id'],
'categoryId': dict_elem['category']['categoryId'],
'categoryName': dict_elem['category']['wholeCategoryName'],
'channelName': dict_elem['channel']['channelName'],
'productNo': dict_elem['productNo'],
'salePrice': dict_elem['salePrice'],
'productStatusType': dict_elem['productStatusType'],
'discountedSalePrice': dict_elem['benefitsView']['discountedSalePrice'],
'discountedRatio': dict_elem['benefitsView']['discountedRatio'],
'textReviewPoint': dict_elem['benefitsView']['textReviewPoint'],
'photoVideoReviewPoint': dict_elem['benefitsView']['photoVideoReviewPoint'],
'reviewCount': dict_elem['reviewAmount']['totalReviewCount'],
'averageReviewScore': dict_elem['reviewAmount']['averageReviewScore'],
'representativeImageUrl': dict_elem['representativeImageUrl']
}
itemsList.append(items)
item_cnt += 1
print(itemsList)
print(item_cnt)- dict인 items에 넣고, 다시 itemsList에 넣은 후, pandas 모듈을 사용해서 excel로 저장해 봤다.
df = pd.DataFrame(itemsList)
print(df.head())
df.to_excel(uid + '.xlsx', index=False)
지난 11월에 requets와 BeautifulSoup의 다른 방법으로 네이버 쇼핑의 데이터를 가져오는 스크래핑을 해봤었는데, 이 방법이 더 좋은 것 같다.
이렇게 받은 데이터를 DB에 저장하는 방법은 여기 참고
'코딩 연습 > 코딩배우기' 카테고리의 다른 글
| 공공데이터를 활용한 아파트 도로명 주소 등 추출해보기 (0) | 2022.01.18 |
|---|---|
| 웹 페이지 <script> 태그 CDATA, 넌 뭐하는 넘이니... (0) | 2022.01.15 |
| 이미지 다운로드 관련 requests와 requests-html 비교 (0) | 2022.01.11 |
| 동적(JavaScript) 웹 페이지의 json 데이터 형식 이미지 다운로드 (with 파이썬) (0) | 2022.01.11 |
| 11번가 실시간 쇼핑 검색어 추출해서 저장하기(python tkinter) (0) | 2022.01.10 |




댓글