
goodthings4me.tistory.com
■ 파이썬으로 네이버 블로그 항목들 추출하기
- naver.com에서 'askdjango' 검색 후 블로그 섹션 하단의 '블로그더보기' 클릭
- 해당 URL에 대해 최소 조합 파라미터로 다시 조합
https://search.naver.com/search.naver
?
date_from=
&date_option=0
&date_to=
&dup_remove=1
&nso=
&post_blogurl=
&post_blogurl_without=
&query=askdjango
&sm=tab_pge
&srchby=all
&st=sim
&where=post
&start=1
# 최소 조합
&query=askdjango
&where=post
&start=1
▷ 한 페이지만 추출 해보기
requests, BeautifulSoup, css selector 등을 사용해서 블로그 항목 추출
import requests
from bs4 import BeautifulSoup
def naver_blog_search1(q):
url = 'https://search.naver.com/search.naver'
params = {
'query': q,
'where': 'post',
'start': 1,
}
html = requests.get(url, params = params).text
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.select('#elThumbnailResultArea .sh_blog_title'):
print(tag.text, tag['href'])
naver_blog_search1('askdjango')

▷ 각 페이지 대상 블로그 추출하기
- 페이지별 크롤링을 위한 파라미터 start 값 변경을 위해 params dict를 만들고,
- 블로그 list를 저장할 dict(순서있는 dict) 객체를 만들어서 검색된 결과를 저장
- 생성된 dict 객체에 동일한 블로그 list가 대입되지 않도록 if문 추가
- 추출할 페이지 번호를 인자로 받는 추출 함수로 만들어서 사용해보기
import requests
from bs4 import BeautifulSoup
from collections import OrderedDict
from itertools import count
def naver_blog_search2(q, max_page = None):
url = 'https://search.naver.com/search.naver'
post_dict = OrderedDict() # 순서있는 dict
# itertools의 count로 페이지 번호 지정 및 무한 생산
for page in count(1):
params = {
'query': q,
'where': 'post',
'start': (page - 1) * 10 + 1, # 1, 11, 21, ... 101
}
#print(params)
html = requests.get(url, params = params).text
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.select('#elThumbnailResultArea .sh_blog_title'):
if tag['href'] in post_dict:
return post_dict
post_dict[tag['href']] = tag.text
if max_page and page >= max_page:
break
return post_dict
result = naver_blog_search2('AskDjango', 2)
print(len(result)) # 20
▷ 블로그 posting 날짜 포함하는 코드
import requests
from bs4 import BeautifulSoup
def naver_blog_search3(query, page_nums):
url = 'https://search.naver.com/search.naver'
post_dict = dict()
page_num = (page_nums * 10) - 9
for page in range(1, page_num + 1, 10):
params = {
'query': query,
'where': 'post',
'start': page,
}
html = requests.get(url, params = params).text
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.select('#elThumbnailResultArea .sh_blog_top dl'):
tag_href = tag.find(class_ = 'sh_blog_title')['href']
tag_title = tag.find(class_ = 'sh_blog_title')['title']
tag_date = tag.find(class_ = 'txt_inline').text
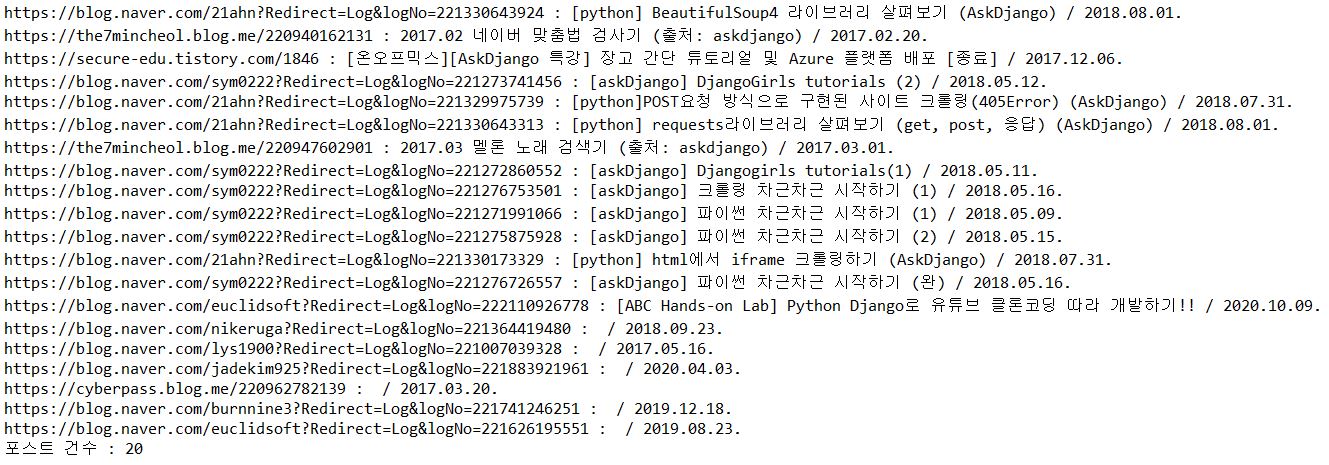
print('{} : {} / {}'.format(tag_href, tag_title, tag_date))
post_dict[tag_href] = tag.text + '/' + tag_date
return post_dict
result = naver_blog_search3('askdjango', 2)
print('포스트 건수 : {}'.format(len(result)))
# 포스트 건수 : 20
[실행 결과]
'코딩 연습 > 코딩배우기' 카테고리의 다른 글
| [python] 파이썬 웹 크롤링(Web Crawling) 알아보기 #5 (0) | 2020.10.21 |
|---|---|
| [python] 파이썬 웹 크롤링(Web Crawling) 알아보기 #4 (0) | 2020.10.20 |
| [python] 파이썬 웹 크롤링(Web Crawling) 알아보기 #2 (0) | 2020.10.16 |
| [python] 파이썬 웹 크롤링(Web Crawling) 알아보기 #1 (0) | 2020.10.15 |
| [python] 파이썬 알고리즘 - 별표 찍기 (0) | 2020.10.14 |

댓글