
goodthings4me.tistory.com
뉴스픽 파트너스 링크 주소를 하나씩 클릭해서 복사 붙여넣기 하는 방식이 아니라 좌우 스크롤되는 기사 20개와 추천 콘텐츠 10개 링크 주소를 한 번에 복사할 수 있도록 파이썬으로 코딩해보았다.
파이썬으로 뉴스픽 파트너스 기사 링크 주소 가져오기
얼마 전에 뉴스픽 파트너스 관련 포스팅을 했는데, 여러 기사에 대해 파이썬 크롤링으로 링크 주소를 가져오는 방법을 작성해보고 그 결과를 다시 포스팅한다.
셀레니움 모듈 import, 크롬 드라이브 사용
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time
import pyperclip
import pyautogui
import openpyxl
from datetime import datetime
def chromeWebdriver():
chrome_service = ChromeService(executable_path=ChromeDriverManager().install())
options = Options()
options.add_experimental_option('detach', True)
options.add_experimental_option('excludeSwitches', ['enable-logging'])
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')
# options.add_argument('--headless')
driver = webdriver.Chrome(service=chrome_service, options=options)
return driver- 크롬 드라이브는 위 코드처럼 함수로 만들어서 사용하면 편리함
셀레니움으로 뉴스픽 파트너스 로그인 하기
driver = chromeWebdriver()
driver.get('https://partners.newspic.kr/login')
driver.implicitly_wait(2)
# driver.maximize_window()
time.sleep(2)
id = driver.find_element(By.NAME, 'id')
id.click()
pyperclip.copy('아이디_메일')
pyautogui.hotkey('ctrl', 'v')
time.sleep(1)
pw = driver.find_element(By.NAME, 'password')
pw.click()
pyperclip.copy('패스워드')
pyautogui.hotkey('ctrl', 'v')
time.sleep(1)
login_btn = driver.find_element(By.XPATH, '/html/body/div[1]/section/div[2]/div/div[1]/form/button')
login_btn.click()
time.sleep(2)- 크롬 드라이브 함수를 호출하고,
- 뉴스픽 파트너스에 셀레니움으로 로그인 절차를 수행한다. 아이디는 이메일이고 패스워드를 넣어주면 크롬 드라이브를 통해 뉴스픽 파트너스 브라우저가 자동으로 오픈되고 로그인이 된다.
- send_keys()를 사용할 수 있으나 간혹 막히는 경우가 있어서 pyperclip과 pyautogui를 사용함
좌우 스크롤 기사의 링크주소 가져오기
## 섹션1 - 좌우스크롤
now = datetime.now()
xl_filename = '뉴스픽_' + now.strftime('%Y%m%d%H%M%S') + '.xlsx'
wb = openpyxl.Workbook()
ws = wb.active
ws.append(['No', '기사 URL', '이미지', '기사 제목', '비고'])
wb.save(xl_filename)
news_scrap = []
scrap = []
newsList_ul = driver.find_element(By.ID, 'profitNewsList')
lis = newsList_ul.find_elements(By.CLASS_NAME, 'swiper-slide')
print(len(lis))
row = 2
for li in lis:
_image = li.find_element(By.CSS_SELECTOR, 'div.thumb > img').get_attribute('src')
title = li.find_element(By.CSS_SELECTOR, 'div.thumb > div.box-share > ul > li:nth-child(1) > button').get_attribute('data-title')
link_url = li.find_element(By.CSS_SELECTOR, 'div.box-share > a').get_attribute('href')
_link_url = link_url.replace('http://', 'https://').replace('&lcp', '&cp')
link_list = _link_url.split('&')
final_url_link = ''
idx = 0
for link in link_list:
if idx == 3:
continue
final_url_link += link + '&'
final_url_link = final_url_link[:-1]
print(f'{_image}\n{title}\n{link_url}\n{final_url_link}')
## 엑셀 저장
ws.cell(row, 1).value = row - 1
ws.cell(row, 2).value = final_url_link
ws.cell(row, 3).value = _image
ws.cell(row, 4).value = title.strip()
ws.cell(row, 5).value = f'="<center><a href=\'"&B{row}&"\' target=\'_blank\' rel=\'noopener\'><img src=\'"&C{row}&"\'><br /><b>"&D{row}&"</b></a></center><br />"'
row += 1
wb.save(xl_filename)- 엑셀 파일을 생성하고, 셀레니움으로 html 구문에서 기사 썸네일 URL, 기사 제목, 파트너스 링크 주소를 추출한다.
- 이때 단축 URL에 맞는 파트너스 URL로 변경하기 위해 replace() 함수를 사용했다.
- 기사 링크 주소 등을 엑셀에 저장하는 이유는 기사 관리를 위한 것이고 마지막 열에 html 코드를 넣어 엑셀 값 만을 복사하여 웹 페이지 등에 바로 붙여넣기 하기 위해서임

추천 콘텐츠 링크 주소 복사하기
## 섹션2
recommend_ul = driver.find_element(By.ID, 'recommendNewsList')
recommend_lis = recommend_ul.find_elements(By.CSS_SELECTOR, 'li.d-flex')
print(len(recommend_lis))
for li in recommend_lis:
_image2 = li.find_element(By.CSS_SELECTOR, 'div.thumb > a > img').get_attribute('src')
title2 = li.find_element(By.CSS_SELECTOR, 'div.info > a > span').text
link_url2 = li.find_element(By.CSS_SELECTOR, 'div.info > a').get_attribute('href')
_link_url2 = link_url2.replace('http://', 'https://').replace('&lcp', '&cp')
link_list2 = _link_url2.split('&')
final_url_link2 = ''
idx = 0
for link in link_list2:
if idx == 3:
continue
final_url_link2 += link + '&'
final_url_link2 = final_url_link2[:-1]
print(f'{_image2}\n{title2}\n{link_url2}\n{final_url_link2}')
## 엑셀 저장
ws.cell(row, 1).value = row - 1
ws.cell(row, 2).value = final_url_link2
ws.cell(row, 3).value = _image2
ws.cell(row, 4).value = title2.strip()
ws.cell(row, 5).value = f'="<center><a href=\'"&B{row}&"\' target=\'_blank\' rel=\'noopener\'><img src=\'"&C{row}&"\'><br /><b>"&D{row}&"</b></a></center><br />"'
row += 1
wb.save(xl_filename)
driver.quit()- 이 부분도 좌우 스크롤 부분과 유사한 방식으로 추출하였으며, 엑셀에 같이 저장하여 한번에 웹 페이지에 올릴 수 있도록 하였다.
실행 결과
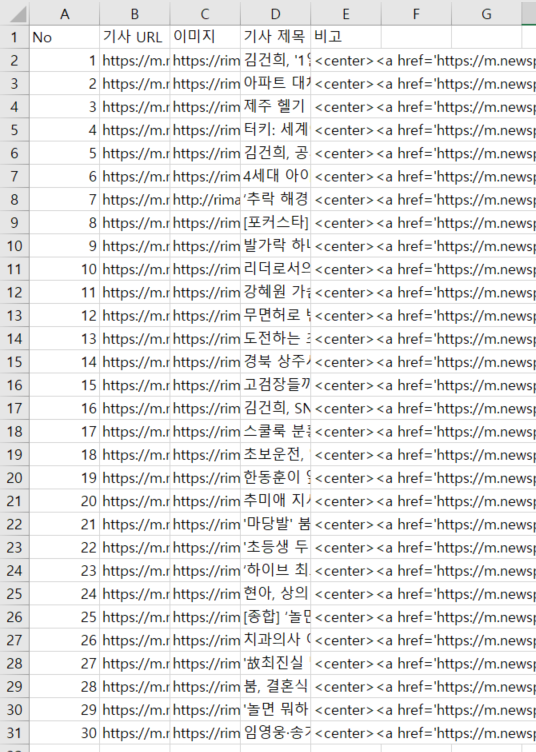
- 엑셀 E열 값을 복사하여 웹 페이지(아래 이미지)에 html 코드 작성으로 삽입

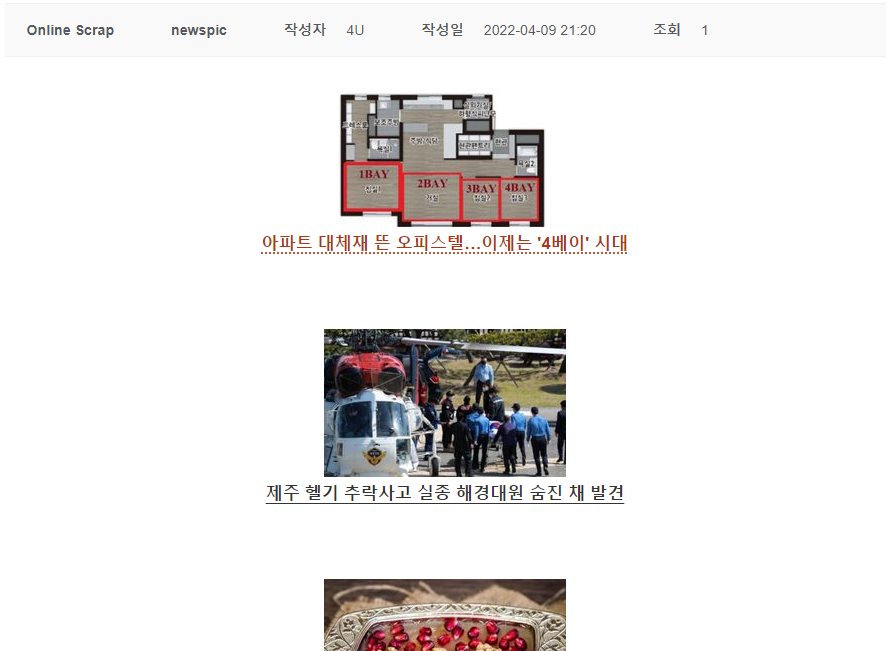
[뉴스픽] 아파트 대체재 뜬 오피스텔…이제는 '4베이' 시대 외
아파트 대체재 뜬 오피스텔…이제는 '4베이' 시대 제주 헬기 추락사고 실종 해경대원 숨진 채 발견 터키: 세계에서 가장 오래된 디저트, 아슈레 푸딩 4세대 아이돌 미드 대표주자 권은비 ‘추락
4u.ne.kr
'코딩 연습 > 코딩배우기' 카테고리의 다른 글
| 숫자 뽑기 게임 - 파이썬 Tkinter로 구현 (0) | 2022.04.11 |
|---|---|
| SSG.COM 실시간 급상승 키워드, 베스트 상품 100위 추출(with 파이썬) (0) | 2022.04.11 |
| openpyxl 엑셀 파일 확장자(.xls) 에러 해결하는 방법 (0) | 2022.04.10 |
| 파이썬 소수 찾기 (0) | 2022.04.09 |
| 다음 영화 이미지 다운로드 - 지식인 문제 해결(파이썬 크롤링 문의) (0) | 2022.04.08 |




댓글