
goodthings4me.tistory.com
네이버 지식in에서 질문한 내용을 답해준 내용으로, 네이버 쇼핑에 노출되는 스마트 스토어 상품의 고객 리뷰(페이지당 20개)에 대해 파이썬 크롤링으로 추출하는 방법을 간단하게 포스팅해보려 한다.
스마트스토어 상품 리뷰를 크롤링으로 추출해하기
※ 기본 틀만 언급하여 전체 내용을 나오도록 하는 방법만 소개하며, 세부적인 내역(평점, 작성일, 상품명, 리뷰글 등)은 자체적으로 해결하도록 함
※ 또한 추출 방법은 질문을 selenium 사용법으로 했기 때문에 selenium으로 해결하는 방법을 설명함
파이썬 크롤링 소스코드는 다음과 같다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time, random
def chromeWebdriver():
chrome_service = ChromeService(executable_path=ChromeDriverManager().install())
options = Options()
options.add_experimental_option('detach', True)
options.add_experimental_option('excludeSwitches', ['enable-logging'])
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')
# options.add_argument('--headless')
driver = webdriver.Chrome(service=chrome_service, options=options)
return driver
url ='https://smartstore.naver.com/blmgshop/products/100061153/'
driver = chromeWebdriver()
driver.get(url)
time.sleep(2)
# review = driver.find_element(By.ID, 'REVIEW') # xpath로 직접하면 필요없음
cnt = 1
for page in range(1, 3):
lis = driver.find_element(By.XPATH, '//*[@id="REVIEW"]/div/div[3]/div/div[2]/ul').find_elements(By.TAG_NAME, 'li')
for li in lis:
print(li.text)
print(f'review_count: {cnt}\n')
cnt += 1
time.sleep(random.uniform(0.5, 1))
# 페이징 처리 부분 (다음 버튼)
driver.find_element(By.XPATH, '//*[@id="REVIEW"]/div/div[3]/div/div[2]/div/div/a[12]')
driver.quit()

- selenium에서 크롬드라이브 사용 시 함수로 만들어서 사용하면 편리함 (다른 곳에 복사하거나 호출하여 사용할 수 있음)
- REVIEW 부분이 css ID로 구분되어 있어서 driver.find_element(By.ID, 'REVIEW')를 사용하려고 하다가 XPATH를 바로 대입해서 처리하니 바로 되었음
- 페이지 처리는 페이지네이션 마지막 '다음'을 XPATH로 잡아서 for 문에 걸어주면 쉽게 해결되었고,
- for page in range(1, 4) 부분에서 4를 큰 수로 바꾸면 그만큼의 페이지 처리가 가능하며, 여기의 page는 사용하지 않아도 됨
- 서버에 영향을 덜 주기 위해 time(), random()으로 조정을 해줌
[추출 결과]
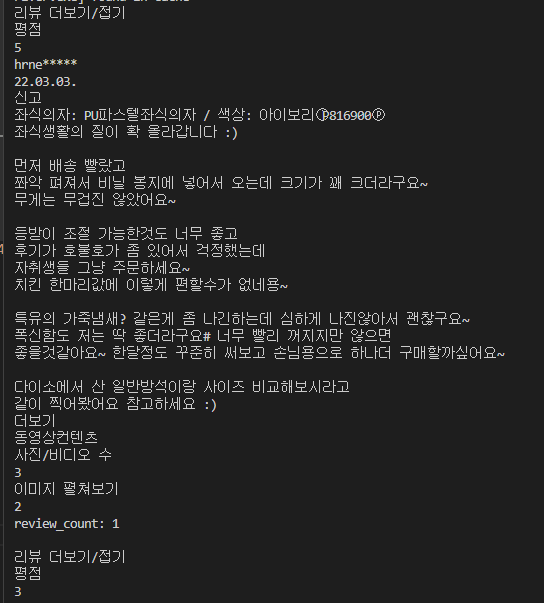
'코딩 연습 > 파이썬 크롤링' 카테고리의 다른 글
| 네이버 뉴스 크롤링 - 기사 제목과 링크(URL) 추출 (0) | 2022.05.16 |
|---|---|
| 티스토리 블로그 내 이미지 다운로드 (0) | 2022.05.10 |
| 네이버 뉴스 감정 표시 숫자 추출하기 (0) | 2022.04.27 |
| 네이트 실시간검색어 (0) | 2022.04.25 |
| 크롤링 - 교보문고 도서 리스트 추출하기 (0) | 2022.04.22 |




댓글