
goodthings4me.tistory.com
네이버에서 로그인이 필요한 웹 페이지에 대해 스크래핑(크롤링)을 하려면 세션을 유지해야 하는데, 셀레니움(selenium)으로 쿠키를 얻은 후, selenium이 아닌 requests.Session 모듈로 쿠키를 보내서 세션을 유지할 수가 있다.
로그인 없이 접속한 경우의 헤더(headers)와 쿠키(cookies)
import requests
from bs4 import BeautifulSoup
def requests_cookie(url):
response = requests.get(url, headers={'User-Agent':'Mozila/5.0'})
print(response.headers) # 응답 headers
print(response.cookies) # <RequestsCookieJar[]>
soup = BeautifulSoup(response.text, 'html.parser')
print(soup) # 결과는 로그인 페이지
requests_cookie('https://mail.naver.com/')네이버 메일에 접근 시, 로그인 페이지로 redirect 된다.
응답 헤더(headers)는
쿠키(cookies)는 # <RequestsCookieJar[]>
BeautifulSoup(response.text, 'html.parser') 인스턴스 객체는 네이버 로그인 페이지의 소스가 출력된다.
<html lang="ko">
<head>
<meta charset="utf-8"/>
<meta content="IE=edge, chrome=1" http-equiv="X-UA-Compatible"/>
<meta content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no" name="viewport"/>
<meta content="website" property="og:type"/>
<meta content="[네이버: 로그인]" property="og:title"/>
<meta content="안전한 로그인을 위해 주소창의 URL과 자물쇠 마크를 확
인하세요!" property="og:description"/>
<meta content="https://ssl.pstatic.net/sstatic/search/common/og_v3.png" property="og:image"/>
<meta content="image/png" property="og:image:type"/>
<meta content="1200" property="og:image:width"/>
<meta content="1200" property="og:image:height"/>
<title>네이버 : 로그인</title>
<link href="/login/css/global/desktop/w_202105.css?20210812" rel="stylesheet" type="text/css"/>
</head>
<body>
<div class="wrap" id="wrap">
<div class="u_skip"><a href="https://www.naver.com">본문 바로가기</a></div>
<header class="header" role="banner">
<div class="header_inner">
<a class="logo" href="https://www.naver.com">
<h1 class="blind">NAVER</h1>
</a>
.....
셀레니움으로 네이버 로그인 접속
def reuse_cookies_test(url):
## selenium & chrome webdriver 사용
options = Options()
# options.add_argument('--headless') # 실행 화면 안 보이게 처리 (Background(CLI))
options.add_argument('--no-sandbox') # Bypass OS security model
options.add_argument('--disable-dev-shm-usage')
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome('./chrome_driver/chromedriver.exe', chrome_options=options)
driver.implicitly_wait(5)
driver.get(url)
time.sleep(10) # id & password 입력 시간 (직접 입력)
print(driver.get_cookies)
## <bound method WebDriver.get_cookies of <selenium.webdriver.chrome.webdriver.WebDriver (session="5a3368dddcbb4ea27fa6e1717f9a0d3b")>>
_cookies = driver.get_cookies()
cookie_dict = {}
for cookie in _cookies:
cookie_dict[cookie['name']] = cookie['value']
print(cookie_dict)
driver.quit()- 셀레니움을 이용할 때, id와 password를 자동으로 입력하지 않고 수동으로 입력하기 위해 입력 대기 시간 (time.sleep(10))을 부여한다. (네이버 이외의 로그인 페이지에 활용할 수 있음)
- 네이버 로그인 페이지가 로딩되면 아이디와 패스워드를 입력한다.
- 셀레니움 driver로 네이버 쿠키( driver.get_cookies())를 얻은 후, dict 변수(cookie_dict)에 저장한다.
- selenium으로 관련 데이터를 수집해도 되지만, 셀레니움 웹 드라이버를 종료(drivet.quit())하고 dict 변수에 저장되어있는 응답 cookies를 이용해서 selenium보다 속도가 빠른 requests.Session()으로 스크래핑(클롤링)을 계속 진행한다.
requests.Session() 사용하기
session = requests.Session()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62',
}
print(session.headers)
print(session.cookies)
session.headers.update(headers) # User-Agent 변경
print(session.headers)
## {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
session.cookies.update(cookie_dict) # 응답받은 cookies로 변경
print(session.cookies)- requests.Session() 객체를 생성한 후 session.headers와 session.cookies를 출력하면,
{'User-Agent': 'python-requests/2.26.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
<RequestsCookieJar[]>- 요청 시 온전한 User-Agent를 위해 headers를 추가(업데이트)한다.
- 세션 유지를 위해 selenium 로그인으로 응답받아 저장한 cookies를 추가(업데이트)하고, 출력된 내용을 보면,
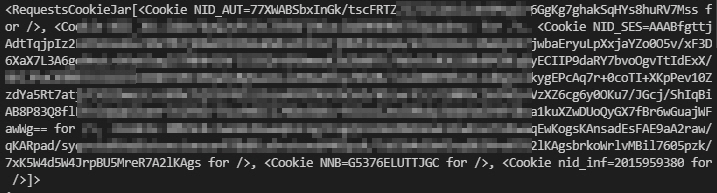
headers & cookies가 추가된 session 객체 활용하여 get() 처리해보기
res = session.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
with open('pay.txt', 'w', encoding='utf-8') as f: # 확인해보기 위해 저장
f.write(soup.text)
unread_find = len(soup.find_all('span', id='unreadMailCount'))
print(unread_find) # 2- https://mail.naver.com 에 대해 session.get() 처리한 경우, 처음과 달리 로그인 페이지가 아닌 메일 페이지로 이동되고,
- 읽지 않은 메일 숫자를 가져오니 '2'라는 숫자가 출력되는 것을 확인할 수 있었다.
위 소스 코드를 활용하면, 다른 로그인 웹 사이트에 대해서도 세션을 유지하여 스크래핑(크롤링)할 수 있을 거 같다.
'코딩 연습 > 코딩배우기' 카테고리의 다른 글
| 11번가 실시간 쇼핑 검색어 추출해서 저장하기(python tkinter) (0) | 2022.01.10 |
|---|---|
| 단축 URL 스크래핑에 파이썬 비동기 처리 개념 적용해보기 (0) | 2022.01.07 |
| 웹 브라우저 페이지를 자동으로 스크롤 해보기 (with 파이썬) (0) | 2021.12.28 |
| 블로그 글 내용 저장 중 이모지 '\U0001f970' 에러 발생 (파이썬) (0) | 2021.12.26 |
| 파이썬 selenium 라이브러리 - find_elements_by_* commands are deprecated. (0) | 2021.12.25 |



댓글