
goodthings4me.tistory.com

데이터 분석을 위한 데이터 수집 시 파일이 아닌 DB에 수집 데이터를 저장하기 위해서는 Oracle이나 MySQL 등의 DB를 사용하는데, 이때 기본으로 알아야 하는 것이 SQL입니다.
이번 포스팅에서는 오라클 11g와 오라클 DBMS 툴인 Oracle SQL Developer의 설치와 기본적인 SQL 문법 등을 연습하고 정리한 내용을 올려봅니다.
DB와 DBMS란?
우리가 데이터베이스에 대해 말할 때 DB(Database) 또는 DBMS(Database Management System)라고 하는데, 이 둘은 정확히 같은 것은 아니지만 보통은 같은 의미로 언급하고 받아들인다.
DB와 DBMS를 구분해서 간략하게 말한다면, 다음과 같다
▶ DB는
- 논리적으로 연관된 데이터를 모아 일정한 형태로 저장해 놓은것
- 응용 시스템들이 공용으로 사용하기 위해 통합, 저장한 데이터 집합
▶ DBMS는
- 데이터 베이스 관리 프로그램
- DBMS를 이용하여 데이터 입력, 수정, 삭제 등의 기능을 제공
데이터베이스는 '구조화된 데이터의 집합'으로 아래와 같은 특성이 있다.
- 여러 사람과 실시간으로 공유하여 사용
- 효율적인 데이터 관리
- 효율적인 데이터 검색
- 일관성 있는 방법으로 데이터 관리
- 데이터 누락 및 중복 제거 등
데이터베이스의 종류
데이터베이스 종류에는 네트워크형 데이터베이스, 계층형 데이터베이스, 그리고 현재까지도 주를 이루는 관계형 데이터베이스( RELATIONAL DATABASE )등이 있으나
최근 트렌트에 따라 비 관계형 데이터베이스(NON-RELATIONAL DATABASE )의 활용 빈도도 증가하고 있다.
▶ 대표적인 데이터베이스 종류
| RELATIONAL DATABASE | NON-RELATIONAL DATABASE |
| ORACLE®, PostgreSQL, MySQL, Microsoft Server SQLite |
redis, mongoDB, АРАСНЕ HBASE, cassandra |
▶ 관계형 데이터베이스(Relational DBMS)
관계형 데이터베이스는 행과 열의 형태로 관리가 되는 구조로 SQL을 가지고 처리를 하며, 현재 대부분의 DB 형태를 이 구조로 사용하고 있다.
관계형 데이터베이스의 주요 특징을 보면,
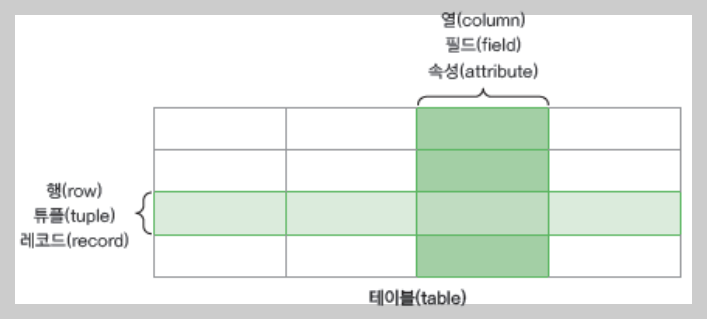
- 테이블(table) 구조로 이루어짐 (엑셀의 시트로 비유됨)
- 고유키(Primary Key)를 통하여 중복 데이터 제거 (중복될 수 없는 키, 사람의 주민등록번호처럼 오직 하나만 존재하여 데이터를 구분할 수 있는 키)
- 행(row) 단위로 데이터를 저장하며 각 항목은 열(column)로 구분함
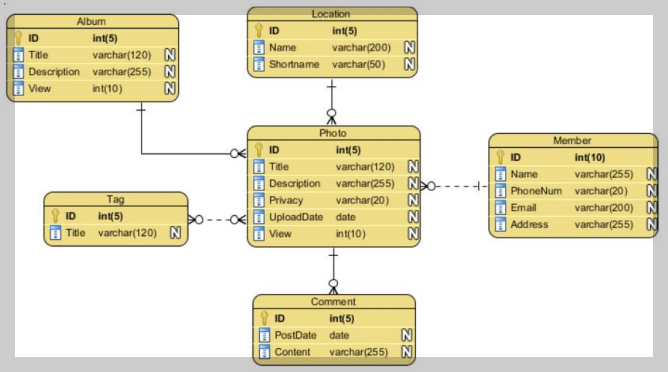
- 테이블(table) 간의 관계를 이용하여 데이터를 정의 - 엑셀 형태를 가지고 있는 구조로 "가로는 행(row), 튜플(tuple), 레코드(record)", "세로는 열(column), 필드(field), 속성(attribute)"으로 칭함

▶ NoSQL(Not Only SQL)
최근 빅데이터와 인공지능 등의 영향으로 비정형 데이터의 저장이 요구되고 있고, 이런 영향으로 비 관계형 데이터베이스 중 데이터 관리의 트렌드로 부상하고 있는 NoSQL이라는 대표적인 형태가 있다.
NoSQL은 다양한 기법으로 관리를 할 수가 있는데, 대표적인 것이 키와 값을 가지는 구조(json 타입)이며 몽고DB, 레디스, 아파치 HBASE, 카산드라가 데이터베이스가 있다.
NoSQL의 특징을 살펴보면,
- 관계형 데이터베이스가 아닌 다른 형태의 저장 기술
- 다양한 기법이 존재하며 그 중 대표적인 방식인 키-값 저장
- 자유로운 데이터 구조가 가능하여 비정형데이터 저장이 용이함
- 중복이 가능하며 데이터 확장에 용이함
- 키-값 외에도 다큐먼트, wide-column, 그래프 등 종류가 다양함

SQL(Structured Query Language)이란?
SQL이란, 데이터베이스에서 데이터 조작과 정의를 하기 위해 사용하는 언어(DATABASE를 다루는 언어)이며,
보통 데이터를 입력/조회/수정/삭제(CRUD)를 하기 위해 사용하는데,
사용 용도에 따라 DDL, DML, DCL 등으로 구분한다. 즉, DDL, DML, DCL로 구분하는 SQL 명령어를 통해 데이터베이스, 테이블, 데이터를 다룰 수 있다.
- DDL(Data Definition Language) 데이터 정의 언어(데이터베이스, 테이블 등) : CREATE, ALTER, DROP
- DML(Data Manipulation Language) 데이터 조작 언어(테이블의 데이터를 조작) : SELECT, INSERT, UPDATE, DELETE
- DCL(Data Control Language) 데이터 제어 언어(데이터베이스 접근 또는 권한 부여) : GRANT, REVOKE, COMMIT, ROLLBACK
DDL(Data Definition Language)
데이터베이스 객체(user, table 등) 관리 (데이터 정의)
- CREATE : 데이터베이스 객체 생성
- DROP : 데이터베이스 객체 삭제
- ALTER : 데이터베이스 객체를 재정의
▶ CREATE
기본구조는
CREATE USER [유저] identified by [비밀번호];
CREATE TABLE [사용자.테이블명] [ [컬럼] [데이터타입](크기) [제약조건]);
create user test identified by 1234;
create table tbtest (name varchar(20));
create table tbtest2 (name varchar(20) not null);
※ 오라클 데이터 타입
아래는 오라클에서 주로 사용하는 데이터타입이며, 이외에도 다양한 데이터타입 있음

▶ DROP 기본 구조
DROP USER [유저명];
DROP TABLE (E);
drop table tbtest;
▶ ALTER 기본 구조
특정 유저, 테이블의 정보 변경 시 사용하는 명령으로 CREATE랑 비슷함
ALTER USER [유저명] IDENTIFIED BY [비밀번호];
ALTER TABLE [테이블명] ADD [컬럼명] [data_type];
alter user test identified by 1234;
alter table tbtest2 add age number(3);
고유키, 참조키(외래키)
고유키(Primary key) : 테이블이 가지는 고유값으로 UNIQUE 하면서 NOT NULL 하는 제약조건
참조키(Foreign key) : 테이블 사이의 관계에서 발생하는 개념이며, 주종관계에 의해서 발생한다.
▶ 고유키(PK)
create table test1 (juminno varchar(20) primary key);
create table test2 (juminno varchar(20) constraint pk_test2 primary key);
- constraint 키워드가 없는 경우, 시스템이 자동으로 제약조건을 관리(SYS_C00700)하고,
- constraint pk_test2처럼 이름을 지정하는 경우, 해당 이름으로 관리(PK_TEST2)가 가능함
▶ 참조키(FK)
alter table test1
add constraint fk_juminno foreign key(juminno) references test2 (juminno);
# 참조키(foreign key)는 test2 테이블을 참조(references test2)하여 juminno에 설정(foreign key(juminno)하되, 제약조건 이름은 fk_juminno로 하여 테이블 test1을 변경하라

테이블 생성 시 참조키를 지정할 수도 있으나 참조 대상 테이블의 고유키를 참조하는 관계로 테이블을 생성 후 에 alter 명령을 통해 참조키를 생성하는 것이 좋음

DCL(Data Control Language)
사용자 권한 제어, 데이터 제어
- GRANT : 데이터베이스 객체에 권한 부여
- REVOKE : 데이터베이스 객체에 부여된 권한 취소
▶ GRANT 기본 구조
GRANT [권한] TO [유저명];
grant create user, alter user, drop user to scott;
▶ REVOKE 기본 구조
REVOKE [권한] FROM [유저명];
revoke create user, alter user, drop user from scott;
# 오라클 데이터베이스에서 계정에 부여할 수 있는 권한은 많으나 사용자 계정을 위한 권한은 아래 권한을 부여함
- RESOURCE : 개체 생성, 변경, 제거
- CONNECT: DB 연결 권한
- DBA: DB 관리자 권한
DML(Data Manipulation Language)
데이터 조작 언어
- SELECT : 데이터 조회(Read)
- INSERT : 데이터 입력(Create)
- UPDATE : 데이터 수정(Update)
- DELETE : 데이터 삭제(delete)
▶ SELECT
SELECT [컬럼명] FROM [테이블명];
select ename from emp;
SELECT [컬럼명1], [컬럼명1], [컬럼명1], ... FROM [테이블명];
select ename, job, deptno from emp;
▶ INSERT
INSERT INTO [테이블명] VALUES (테이터1, 테이터2,..., 데이터n);
insert into emp values (1, 'kim', 'teacher', null, null, null, null, null);
* cf) 오라클에서는 따옴표는 테이블이나 컬럼명 등 개체인 경우는 " "를 사용하고, 데이터(문자 또는 문자열)인 경우는 ' '를 사용함
INSERT ALL INTO [테이블명] VALUES ( (테이터1, 테이터2,..., 데이터n) INTO [테이블명] VALUES (테이터1, 테이터2,..., 데이터n) SELECT * FROM dual;
insert all into emp values (2, 'kim', 'teacher', null, null, null, null, null)
into emp values (3, 'kim', 'teacher', null, null, null, null, null)
select * from dual;
INSERT INTO [테이블명] (컬럼명1, 컬럼명2, ...) VALUES (테이터1, 테이터2,...);
insert into emp (empno, ename) values (4, 'park');
▶ UPDATE
UPDATA [테이블명] SET [컬럼명2] = [데이터1], ..., [컬럼명n] = [데이터n];
update emp set hiredate = to_date('23/03/14');
UPDATA [테이블명] SET [컬럼명2] = [데이터1], ..., [컬럼명n] = [데이터n] WHERE [컬럼] = [데이터];
update emp set ename = 'lee' where empno = 2;
▶ DELETE
DELETE FROM [테이블];
delete from emp;
테이블의 자체가 아닌 데이터 전체가 사라짐. WHERE와 함께 사용
DELETE FROM [테이블] WHERE [컬럼] = [데이터];
delete from emp where ename = 'kim';
where 절
조건을 만족하는 값만 가져오기
SELECT [컬럼명] FROM [테이블명] WHERE [조건];
select * from emp where deptno = 20;
※ 조건 비교 연산자
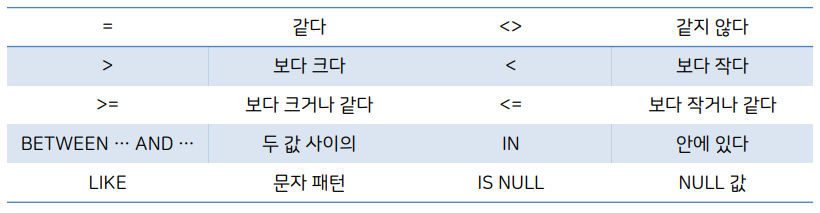
* BETWEEN ~ AND ~ : 이상, 이하 개념 (BETWEEN 1250 AND 1500는 1250 <= 값 <= 1500
* NOT : 조건의 반대로 함. NOT IN 또는 IS NOT NULL, NOT BETWEEN ~ AND ~ 처럼 사용 가능함
* 조건 AND 조건
* 조건 OR 조건
select *
from emp
where sal between 1000 and 2000;
select *
from emp
where job in ('SALESMAN', 'CLERK');
LIKE '%김%'
select *
from emp
where ename like '%A%';
%문자% : 앞뒤 어느 문자열이 와도 상관없이 포함
- %김% : 문자에 '김'이라는 글자가 포함된
- %김 : '~김'으로 끝나는
- 김% : '김~'으로 시작하는
_ : 어떤 것이든 한 문자 허용
select *
from emp
where ename like '_A';
select *
from emp
where ename like '__A';
정렬(ORDER BY)
명시한 컬럼 순서 대로 정렬. 쿼리에서 가장 마지막에 적용함
SELECET [컬럼명] FROM [테이블명] ORDER BY [컬럼1], [컬럼2],..., [컬럼n] ASC[DESC];
*ASC(오름차순, 기본값), DESC(내림차순)
select *
from emp
order by ename;
select *
from emp
order by ename asc;
select *
from emp
order by ename desc;
그룹화(GROUP BY)
같은 값끼리 묶어서 그룹화 생성. 그룹집계함수와 같이 사용
SELECET <그룹집계함수>([컬럼명]) FROM [테이블명] GROUP BY [컬럼1], [컬럼2],...;
*그룹집계함수: COUNT, SUM, AVG, MAX, MIN, STDDEV(표준 편차), VARIANCE(분산)
select count(job)
from emp
group by job;
select job, count(job) as cnt
from emp
group by job
order by cnt asc;- as : 별칭 - 출력 결과의 컬럼명을 변경하여 표시할 때 사용

그룹화 조건 (GROUP BY HAVING)
그룹화 된 결과를 기준으로 조건(HAVING)에 맞게 생성함. WHERE와 유사한 기능
SELECET <그룹함수>([컬럼명]) FROM [테이블명] GROUP BY [컬럼] HAVING <그룹함수>([컬럼]) 비교 조건;
select job, count(job) as cnt
from emp
group by job
having count(job) >= 3;
select job, count(job) as cnt
from emp
where sal > 1000
group by job
having count(job) >= 3;
select job, count(job) as cnt
from emp
where sal > 1000
group by job
having count(job) >= 3
order by cnt asc;
※ 그룹함수 - GROUP BY 없이도 사용 가능

연결(JOIN )
하나 이상의 테이블로부터 데이터를 연결하기 위해 사용함 (테이블을 합쳐서 사용)
SELECET [컬럼]) FROM [테이블1] JOIN [테이블2] ON [테이블1.컬럼] = [테이블2.컬럼];
*단, 컬럼의 데이터 자료 타입이 같아야 함
select *
from emp
join dept
on emp.deptno = dept.deptno;
select *
from emp
left outer join dept
on emp.deptno = dept.deptno;
select *
from emp
right outer join dept
on emp.deptno = dept.deptno;
select *
from emp
full outer join dept
on emp.deptno = dept.deptno;
▶ 조인의 종류에는
| JION(= INNER JOIN) | 양쪽 테이블 컬럼이 존재할 때만 표현 |
| LEFT OUTER JOIN | 왼쪽 기준으로 표현 (오른쪽에 값이 없어도 표현) |
| RIGHT OUTER JOIN | 오른쪽 기준으로 표현 (왼쪽에 값이 없어도 표현) |
| FULL OUTER JOIN | 양쪽 모두 값이 없어도 표현 |
- INNER는 교집합 개념으로,
- OUTER는 JOIN 기준으로 좌(LEFT), 우(RIGHT)를 구분하여 LEFT는 좌측을 전체, RIGHT는 우측을 전체 적용, FULL은 양쪽을 모두 적용함을 의미

시퀀스(SEQUENCE)
테이블를 다루는 것이 아니라 자동으로 숫자를 생성하는 구문으로 이 구문을 통해 특정 컬럼에 규칙적인 숫자를 반영할 수 있음. (예로, 주민번호 생성 규칙)
# 생성되는 곳 : '시퀀스' 개체에 생성됨
CREATE SEQUENCE [시퀀스명] START WITH [시작숫자]
INCREMENT [증가폭] [MAXVALUE [최대값] ᅳ NOMAXVALUE]
[MINVALUE [최소값] NOMINVALUE] [CYCLE | NOCYCLE]
create sequence test_seq start with 1 increment by 1 maxvalue 10000;
create sequence test_seq2 start with 10 increment by 2 nomaxvalue;
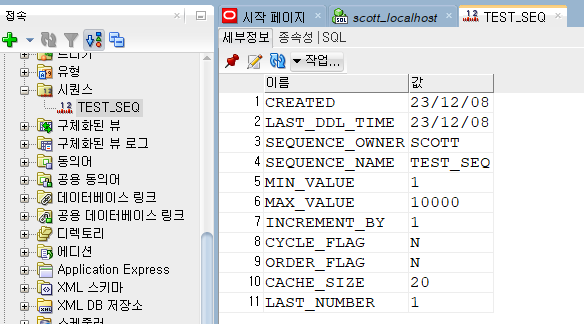
[시퀀스명].N EXTVAL : 다음 숫자
[시퀀스명].CURRVAL : 현재 숫자
select test_seq.nextval from dual;
INSERT 할 때, 자동으로 숫자를 채우면서 저장 가능
insert into emp(empno) values(test_seq.nextval);
SQL 실습하기
실습 테이블은 scott의 테이블을 대상으로 함
/*
가. MGR이 7839인 레코드의 ENAME, JOB 조회
나. ENAME이 SMITH인 레코드의 ENAME을 SMITH2로 수정
다. JOB이 PRESIDENT인 레코드의 HIREDATE를 1981/07/11 로 수정
라. SAL이 3000 이상인 레코드의 모든 컬럼 조회
*/
select ENAME, JOB from emp where MGR = 7839;
update emp set ENAME = 'SMITH2' where ENAME = 'SMITH';
select * from emp where ENAME = 'SMITH2';
update emp set HIREDATE = to_date('1981/07/11') where JOB = 'president';
select * from emp;
select * from emp where SAL >= 3000;
/*
가. ENAME 중 A로 시작하는 레코드 조회
나. ENAME 중 N으로 끝나는 레코드 조회
다. JOB 중 E를 포함하는 레코드 조회
라. HIREDATE가 1981/11/01 보다 크고 ENAME에 R이 포함되어 있는 레코드 조회
*/
select * from emp where ENAME like 'A%';
select * from emp where ENAME like '%N';
select * from emp where JOB like '%E%';
select * from emp where HIREDATE > '1981/11/01' and ENAME like '%R%';
/*
가. EMPNO가 7699 또는 7900인 레코드 조회
나. ENAME이 SCOTT 또는 KING인 레코드 조회
다. JOB이 CLERK 또는 MANAGER이고 SAL이 2500 보다 큰 레코드 조회
라. MGR이 7698 또는 7839 이고 DEPTNO가 10인 레코드 조회
*/
select * from emp where EMPNO in (7699, 7900);
select * from emp where EMPNO = 7699 or EMPNO = 7900;
select * from emp where ENAME = 'SCOTT' or ENAME = 'KING';
select * from emp where JOB in ('CLERK', 'MANAGER') and SAL >= 2500;
/*
가. HIREDATE가 1981/02/20에서 1983/01/01 사이인 레코드 조회
나. HIREDATE가 1981/05/01에서 1981/12/31 사이이고 DEPTNO가 30인 레코드 조회
다. SAL이 2000 에서 3000 사이 이거나 COMM 이 500인 레코드 조회
*/
select * from emp
where HIREDATE
between '1981/02/20' and '1983/01/01';
select * from emp
where HIREDATE
between '1981/02/20' and '1983/01/01'
and DEPTNO = 30;
select * from emp
where SAL
between 2000 and 3000
or COMM = 500;
/* is null / is not null
가. MGR이 NULL인 레코드 조회
나. COMM이 NULL인 레코드 조회
다. MGR이 NULL이 아니고 DEPTNO가 20인 레코드 조회
라. COMM이 NULL이 아니고 COMM이 1000 보다 큰 레코드 조회
*/
select * from emp
where MGR is null;
select * from emp
where COMM is null;
select * from emp
where MGR is not null
and DEPTNO = 20;
select * from emp
where COMM is not null
and COMM > 1000;
/*
가. ENAME의 내림차순으로 모든 레코드 조회
나. HIDEDATE의 오름차순으로 EMPNO, ENAME, HIREDATE 조회
다. DEPTNO의 내림차순으로 정렬하고 DEPTNO가 같은 경우 ENAME의 오름차순으로 정렬하여 조회
*/
select * from emp order by ENAME desc;
select * from emp order by EMPNO, ENAME, HIREDATE asc;
select * from emp order by DEPTNO desc, ENAME asc;
자주 사용하는 SQL 기본 함수, 서브 쿼리, 트랜잭션에 대한 내용은 아래를 참고하세요.
SQL 함수, 서브 쿼리 연습
직전 포스팅(SQL 기본 문법)에 이어서 SQL 함수와 서브 쿼리 연습 후 정리한 내용임. 문자, 숫자, 날짜, 그리고 중복 제거와 관련한 함수를 연습해보고, 서브 쿼리에 대한 내용도 정리해서 올려봅니
goodthings4me.tistory.com
오라클 11g, SQL Developer 설치해보기
파이썬 데이터 분석 연습을 위해 실습용 데이터베이스로 오라클 11g 설치와 오라클 DBMS 툴인 SQL Developer를 설치하고 실행하는 절차를 정리함 오라클의 버전에서 g는 그리드, c는 클라우드를 나타
goodthings4me.tistory.com
'코딩 연습' 카테고리의 다른 글
| 썸네일 이미지 만들기 용량 줄이기(with python) (0) | 2023.12.10 |
|---|---|
| SQL 함수, 서브 쿼리 연습 (0) | 2023.12.08 |
| ImportError: DLL load failed while importing win32clipboard (0) | 2023.11.13 |
| 화면 캡처 이미지 자동 저장 (1) | 2023.04.04 |
| 공동주택 기본 정보제공 서비스 추출 (0) | 2023.03.29 |



댓글