
goodthings4me.tistory.com
도로명 주소(juso.go.kr)의 명칭을 네이버 검색에 입력하면 비슷하지만 다른 명칭이 나오는 경우가 있었다. 네이버의 명칭을 찾기 위해서 도로명 주소를 입력하면 플레이스 페이지로 연결되고, 여기에 명칭과 지번주소가 있다.
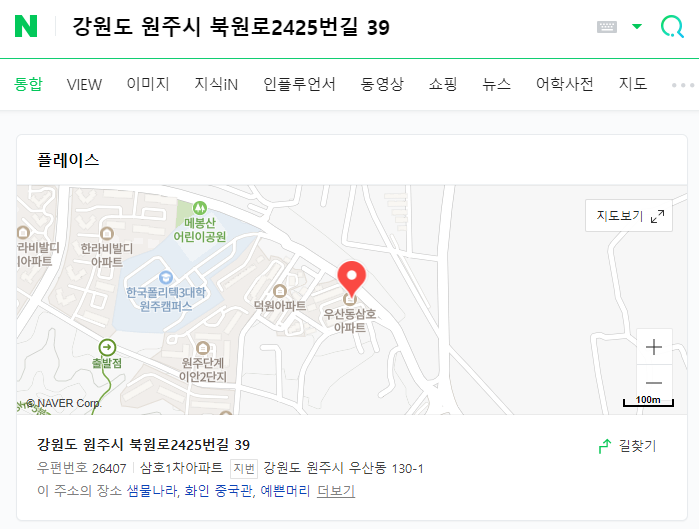
네이버 검색에서 "강원도 원주시 북원로2425번길 39"로 검색 시 위 이미지처럼 네이버 플레이스 페이지로 이동된 것을 볼 수 있는데, 여기서 파이썬을 활용하여 엑셀의 도로명주소를 읽고 그 주소를 검색한 후 "우편번호, 명칭, 지번주소"를 추출하여 텍스트로 저장해보자.
도로명주소로 우편번호, 명칭, 지번주소 추출하기
추출에 이용할 도로명주소가 있는 엑셀 샘플은 다음과 같다.
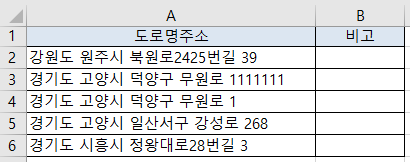
[파이썬 소스 코드]
import requests
from bs4 import BeautifulSoup
import openpyxl
import time, random
## 엑셀 파일 읽기 - 워크북, 워크시트
wb1 = openpyxl.load_workbook('./roadjuso.xlsx')
ws1 = wb1['Sheet1'] # wb1.active
maxRow = ws1.max_row # 최대 row
# print(maxRow)
headers = {
'user_agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
}
row = 2
for r in range(2, maxRow + 1):
target_row = ws1.cell(r, 1).value # 셀 읽어오기
print(f'\ntarget_row [{r}:3] {target_row}')
url = 'https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=' + target_row
response = requests.get(url, headers=headers)
time.sleep(random.uniform(0.5, 1))
soup = BeautifulSoup(response.text, 'html.parser')
try:
road = soup.find('div', class_='ITiBH').text.strip()
name_lot = soup.find_all('span', class_='_3rnws')
zip = name_lot[0].text.replace('우편번호', '').strip()
name = name_lot[1].text.split('지번')[0].strip()
lot = name_lot[1].text.split('지번')[1].strip()
print(f'도로명주소: {road}\n우편번호: {zip}\n건물명칭: {name}\n지번주소: {lot}\n')
except:
print('오류: 못찾음!!')
ws1.cell(r, 2).value = 'error'
wb1.save('./roadjuso.xlsx')
continue
# 추출데이터 저장 형식
txt_insert = target_row + '$' + road + '$' + zip + '$' + name + '$' + lot + '\n'
with open('./naver_juso.txt', 'a') as f:
f.write(txt_insert)
print(f'target_row #{r} 저장 완료!!')
time.sleep(random.uniform(0.5, 1))
# if row == 10:
# break
wb1.close()
print('작업 완료!!!')페이지 소스를 보니 바로 추출이 가능한 형태였음
네이버에서 자료 추출 시 headers는 필수!!

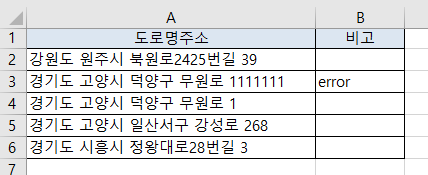
[실행 결과]
target_row [2:3] 강원도 원주시 북원로2425번길 39
도로명주소: 강원도 원주시 북원로2425번길 39
우편번호: 26407
건물명칭: 삼호1차아파트
지번주소: 강원도 원주시 우산동 130-1
target_row #2 저장 완료!!
target_row [3:3] 경기도 고양시 덕양구 무원로 1111111
오류: 못찾음!!
target_row [4:3] 경기도 고양시 덕양구 무원로 1
도로명주소: 경기도 고양시 덕양구 무원로 1
우편번호: 10522
건물명칭: 무원마을6단지
지번주소: 경기도 고양시 덕양구 행신동 702
target_row #4 저장 완료!!
target_row [5:3] 경기도 고양시 일산서구 강성로 268
도로명주소: 경기도 고양시 일산서구 강성로 268
우편번호: 10376
건물명칭: 성저마을3단지
지번주소: 경기도 고양시 일산서구 대화동 2215
target_row #5 저장 완료!!
target_row [6:3] 경기도 시흥시 정왕대로28번길 3
도로명주소: 경기도 시흥시 정왕대로28번길 3
우편번호: 15041
건물명칭: 대림1차아파트
지번주소: 경기도 시흥시 정왕동 1863
target_row #6 저장 완료!!
작업 완료!!!

'코딩 연습 > 파이썬 크롤링' 카테고리의 다른 글
| 전원주택라이프 웹 사이트 크롤링 테스트 (0) | 2023.03.25 |
|---|---|
| 네이버 블로그 제목 리스트 추출해보기 (0) | 2022.08.23 |
| 네이버 쇼핑 상품 리스트 추출 후 엑셀 저장 (0) | 2022.07.12 |
| [파이썬 크롤링] 네이버쇼핑 카테고리 추출해보기 (0) | 2022.07.11 |
| 네이버 쇼핑 상세페이지 태그 추출 (0) | 2022.07.07 |




댓글